Detailed Discussion
- -Python (and PyTorch) relies on the memory allocator from the C Standard Library (`libc`). On linux, with the GNU C Standard Library implementation (`glibc`), our memory access patterns have been observed to cause severe memory fragmentation. - -This fragmentation results in large amounts of memory that has been freed but can't be released back to the OS. Loading models from disk and moving them between CPU/CUDA seem to be the operations that contribute most to the fragmentation. - -This memory fragmentation issue can result in OOM crashes during frequent model switching, even if `ram` (the max RAM cache size) is set to a reasonable value (e.g. a OOM crash with `ram=16` on a system with 32GB of RAM). - -This problem may also exist on other OSes, and other `libc` implementations. But, at the time of writing, it has only been investigated on linux with `glibc`. - -To better understand how the `glibc` memory allocator works, see these references: - -- Basics:
-
-| Sampler | (3 sample avg) it/s (M1 Max 64GB, 512x512) |
-|---|---|
-| `DDIM` | 1.89 |
-| `PLMS` | 1.86 |
-| `K_EULER` | 1.86 |
-| `K_LMS` | 1.91 |
-| `K_HEUN` | 0.95 (slower) |
-| `K_DPM_2` | 0.95 (slower) |
-| `K_DPM_2_A` | 0.95 (slower) |
-| `K_EULER_A` | 1.86 |
-
-
-
-!!! tip "suggestions"
-
- For most use cases, `K_LMS`, `K_HEUN` and `K_DPM_2` are the best choices (the latter 2 run 0.5x as quick, but tend to converge 2x as quick as `K_LMS`). At very low steps (≤ `-s8`), `K_HEUN` and `K_DPM_2` are not recommended. Use `K_LMS` instead.
-
- For variability, use `K_EULER_A` (runs 2x as quick as `K_DPM_2_A`).
-
----
-
-### *Sampler results*
-
-Let's start by choosing a prompt and using it with each of our 8 samplers, running it for 10, 20, 30, 40, 50 and 100 steps.
-
-Anime. `"an anime girl" -W512 -H512 -C7.5 -S3031912972`
-
-
-
-### *Sampler convergence*
-
-Immediately, you can notice results tend to converge -that is, as `-s` (step) values increase, images look more and more similar until there comes a point where the image no longer changes.
-
-You can also notice how `DDIM` and `PLMS` eventually tend to converge to K-sampler results as steps are increased.
-Among K-samplers, `K_HEUN` and `K_DPM_2` seem to require the fewest steps to converge, and even at low step counts they are good indicators of the final result. And finally, `K_DPM_2_A` and `K_EULER_A` seem to do a bit of their own thing and don't keep much similarity with the rest of the samplers.
-
-### *Batch generation speedup*
-
-This realization is very useful because it means you don't need to create a batch of 100 images (`-n100`) at `-s100` to choose your favorite 2 or 3 images.
-You can produce the same 100 images at `-s10` to `-s30` using a K-sampler (since they converge faster), get a rough idea of the final result, choose your 2 or 3 favorite ones, and then run `-s100` on those images to polish some details.
-The latter technique is 3-8x as quick.
-
-!!! example
-
- At 60s per 100 steps.
-
- A) 60s * 100 images = 6000s (100 images at `-s100`, manually picking 3 favorites)
-
- B) 6s *100 images + 60s* 3 images = 780s (100 images at `-s10`, manually picking 3 favorites, and running those 3 at `-s100` to polish details)
-
- The result is __1 hour and 40 minutes__ for Variant A, vs __13 minutes__ for Variant B.
-
-### *Topic convergance*
-
-Now, these results seem interesting, but do they hold for other topics? How about nature? Food? People? Animals? Let's try!
-
-Nature. `"valley landscape wallpaper, d&d art, fantasy, painted, 4k, high detail, sharp focus, washed colors, elaborate excellent painted illustration" -W512 -H512 -C7.5 -S1458228930`
-
-
-
-With nature, you can see how initial results are even more indicative of final result -more so than with characters/people. `K_HEUN` and `K_DPM_2` are again the quickest indicators, almost right from the start. Results also converge faster (e.g. `K_HEUN` converged at `-s21`).
-
-Food. `"a hamburger with a bowl of french fries" -W512 -H512 -C7.5 -S4053222918`
-
-
-
-Again, `K_HEUN` and `K_DPM_2` take the fewest number of steps to be good indicators of the final result. `K_DPM_2_A` and `K_EULER_A` seem to incorporate a lot of creativity/variability, capable of producing rotten hamburgers, but also of adding lettuce to the mix. And they're the only samplers that produced an actual 'bowl of fries'!
-
-Animals. `"grown tiger, full body" -W512 -H512 -C7.5 -S3721629802`
-
-
-
-`K_HEUN` and `K_DPM_2` once again require the least number of steps to be indicative of the final result (around `-s30`), while other samplers are still struggling with several tails or malformed back legs.
-
-It also takes longer to converge (for comparison, `K_HEUN` required around 150 steps to converge). This is normal, as producing human/animal faces/bodies is one of the things the model struggles the most with. For these topics, running for more steps will often increase coherence within the composition.
-
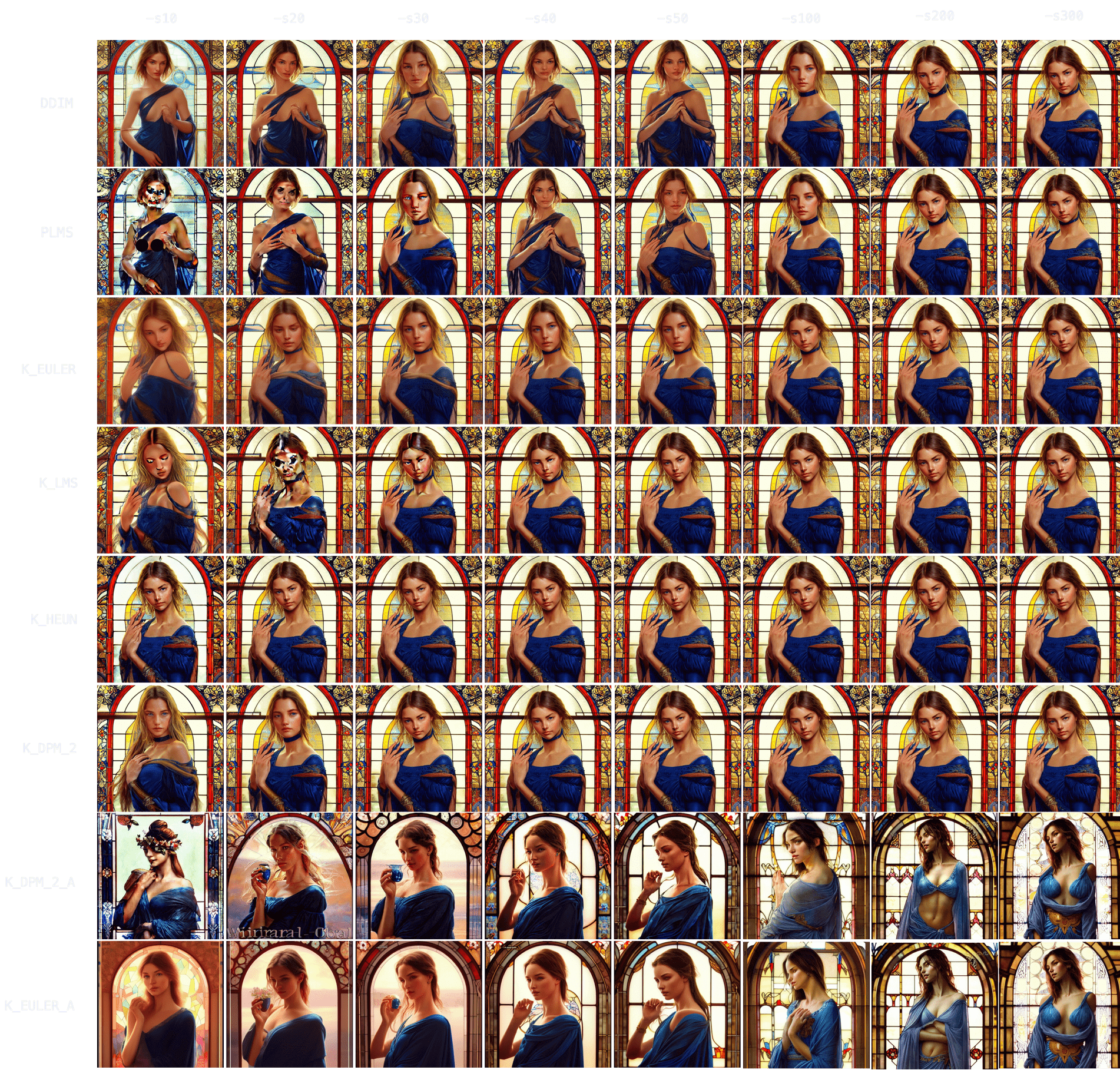
-People. `"Ultra realistic photo, (Miranda Bloom-Kerr), young, stunning model, blue eyes, blond hair, beautiful face, intricate, highly detailed, smooth, art by artgerm and greg rutkowski and alphonse mucha, stained glass" -W512 -H512 -C7.5 -S2131956332`. This time, we will go up to 300 steps.
-
-
-
-Observing the results, it again takes longer for all samplers to converge (`K_HEUN` took around 150 steps), but we can observe good indicative results much earlier (see: `K_HEUN`). Conversely, `DDIM` and `PLMS` are still undergoing moderate changes (see: lace around her neck), even at `-s300`.
-
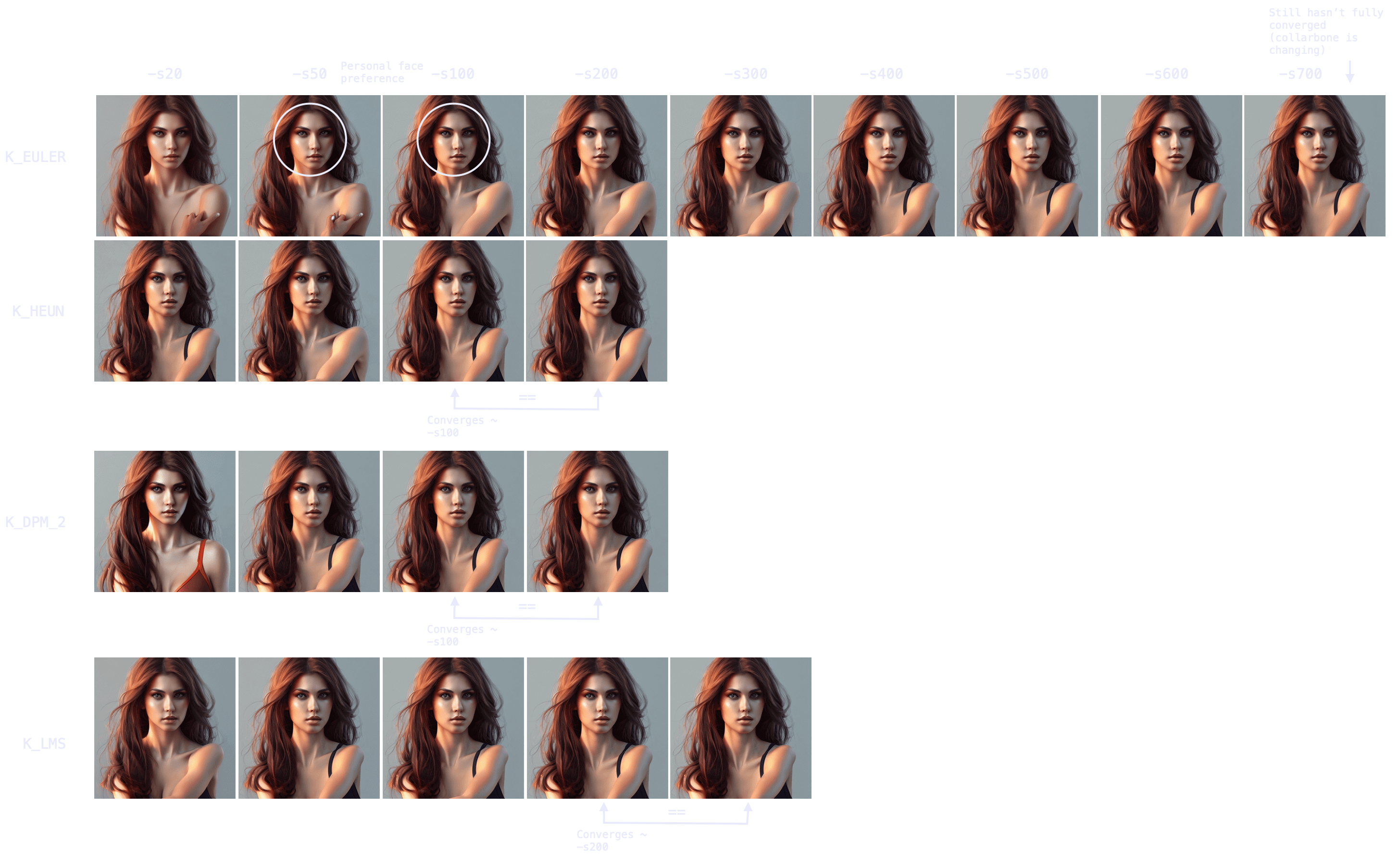
-In fact, as we can see in this other experiment, some samplers can take 700+ steps to converge when generating people.
-
-
-
-Note also the point of convergence may not be the most desirable state (e.g. I prefer an earlier version of the face, more rounded), but it will probably be the most coherent arms/hands/face attributes-wise. You can always merge different images with a photo editing tool and pass it through `img2img` to smoothen the composition.
-
-### *Sampler generation times*
-
-Once we understand the concept of sampler convergence, we must look into the performance of each sampler in terms of steps (iterations) per second, as not all samplers run at the same speed.
-
-
-
-On my M1 Max with 64GB of RAM, for a 512x512 image
-
-| Sampler | (3 sample average) it/s |
-| :--- | :--- |
-| `DDIM` | 1.89 |
-| `PLMS` | 1.86 |
-| `K_EULER` | 1.86 |
-| `K_LMS` | 1.91 |
-| `K_HEUN` | 0.95 (slower) |
-| `K_DPM_2` | 0.95 (slower) |
-| `K_DPM_2_A` | 0.95 (slower) |
-| `K_EULER_A` | 1.86 |
-
-
-
-Combining our results with the steps per second of each sampler, three choices come out on top: `K_LMS`, `K_HEUN` and `K_DPM_2` (where the latter two run 0.5x as quick but tend to converge 2x as quick as `K_LMS`). For creativity and a lot of variation between iterations, `K_EULER_A` can be a good choice (which runs 2x as quick as `K_DPM_2_A`).
-
-Additionally, image generation at very low steps (≤ `-s8`) is not recommended for `K_HEUN` and `K_DPM_2`. Use `K_LMS` instead.
-
-{ width=600}
-
-### *Three key points*
-
-Finally, it is relevant to mention that, in general, there are 3 important moments in the process of image formation as steps increase:
-
-* The (earliest) point at which an image becomes a good indicator of the final result (useful for batch generation at low step values, to then improve the quality/coherence of the chosen images via running the same prompt and seed for more steps).
-
-* The (earliest) point at which an image becomes coherent, even if different from the result if steps are increased (useful for batch generation at low step values, where quality/coherence is improved via techniques other than increasing the steps -e.g. via inpainting).
-
-* The point at which an image fully converges.
-
-Hence, remember that your workflow/strategy should define your optimal number of steps, even for the same prompt and seed (for example, if you seek full convergence, you may run `K_LMS` for `-s200` in the case of the red-haired girl, but `K_LMS` and `-s20`-taking one tenth the time- may do as well if your workflow includes adding small details, such as the missing shoulder strap, via `img2img`).
diff --git a/docs/help/diffusion.md b/docs/help/diffusion.md
deleted file mode 100644
index 7182a51d67f..00000000000
--- a/docs/help/diffusion.md
+++ /dev/null
@@ -1,27 +0,0 @@
-Taking the time to understand the diffusion process will help you to understand how to more effectively use InvokeAI.
-
-There are two main ways Stable Diffusion works - with images, and latents.
-
-Image space represents images in pixel form that you look at. Latent space represents compressed inputs. It’s in latent space that Stable Diffusion processes images. A VAE (Variational Auto Encoder) is responsible for compressing and encoding inputs into latent space, as well as decoding outputs back into image space.
-
-To fully understand the diffusion process, we need to understand a few more terms: UNet, CLIP, and conditioning.
-
-A U-Net is a model trained on a large number of latent images with with known amounts of random noise added. This means that the U-Net can be given a slightly noisy image and it will predict the pattern of noise needed to subtract from the image in order to recover the original.
-
-CLIP is a model that tokenizes and encodes text into conditioning. This conditioning guides the model during the denoising steps to produce a new image.
-
-The U-Net and CLIP work together during the image generation process at each denoising step, with the U-Net removing noise in such a way that the result is similar to images in the U-Net’s training set, while CLIP guides the U-Net towards creating images that are most similar to the prompt.
-
-
-When you generate an image using text-to-image, multiple steps occur in latent space:
-1. Random noise is generated at the chosen height and width. The noise’s characteristics are dictated by seed. This noise tensor is passed into latent space. We’ll call this noise A.
-2. Using a model’s U-Net, a noise predictor examines noise A, and the words tokenized by CLIP from your prompt (conditioning). It generates its own noise tensor to predict what the final image might look like in latent space. We’ll call this noise B.
-3. Noise B is subtracted from noise A in an attempt to create a latent image consistent with the prompt. This step is repeated for the number of sampler steps chosen.
-4. The VAE decodes the final latent image from latent space into image space.
-
-Image-to-image is a similar process, with only step 1 being different:
-1. The input image is encoded from image space into latent space by the VAE. Noise is then added to the input latent image. Denoising Strength dictates how many noise steps are added, and the amount of noise added at each step. A Denoising Strength of 0 means there are 0 steps and no noise added, resulting in an unchanged image, while a Denoising Strength of 1 results in the image being completely replaced with noise and a full set of denoising steps are performance. The process is then the same as steps 2-4 in the text-to-image process.
-
-Furthermore, a model provides the CLIP prompt tokenizer, the VAE, and a U-Net (where noise prediction occurs given a prompt and initial noise tensor).
-
-A noise scheduler (eg. DPM++ 2M Karras) schedules the subtraction of noise from the latent image across the sampler steps chosen (step 3 above). Less noise is usually subtracted at higher sampler steps.
diff --git a/docs/help/gettingStartedWithAI.md b/docs/help/gettingStartedWithAI.md
deleted file mode 100644
index 617bd604010..00000000000
--- a/docs/help/gettingStartedWithAI.md
+++ /dev/null
@@ -1,97 +0,0 @@
-# Getting Started with AI Image Generation
-
-New to image generation with AI? You’re in the right place!
-
-This is a high level walkthrough of some of the concepts and terms you’ll see as you start using InvokeAI. Please note, this is not an exhaustive guide and may be out of date due to the rapidly changing nature of the space.
-
-## Using InvokeAI
-
-### **Prompt Crafting**
-
-- Prompts are the basis of using InvokeAI, providing the models directions on what to generate. As a general rule of thumb, the more detailed your prompt is, the better your result will be.
-
- *To get started, here’s an easy template to use for structuring your prompts:*
-
-- Subject, Style, Quality, Aesthetic
- - **Subject:** What your image will be about. E.g. “a futuristic city with trains”, “penguins floating on icebergs”, “friends sharing beers”
- - **Style:** The style or medium in which your image will be in. E.g. “photograph”, “pencil sketch”, “oil paints”, or “pop art”, “cubism”, “abstract”
- - **Quality:** A particular aspect or trait that you would like to see emphasized in your image. E.g. "award-winning", "featured in {relevant set of high quality works}", "professionally acclaimed". Many people often use "masterpiece".
- - **Aesthetics:** The visual impact and design of the artwork. This can be colors, mood, lighting, setting, etc.
-- There are two prompt boxes: *Positive Prompt* & *Negative Prompt*.
- - A **Positive** Prompt includes words you want the model to reference when creating an image.
- - Negative Prompt is for anything you want the model to eliminate when creating an image. It doesn’t always interpret things exactly the way you would, but helps control the generation process. Always try to include a few terms - you can typically use lower quality image terms like “blurry” or “distorted” with good success.
-- Some examples prompts you can try on your own:
- - A detailed oil painting of a tranquil forest at sunset with vibrant+ colors and soft, golden light filtering through the trees
- - friends sharing beers in a busy city, realistic colored pencil sketch, twilight, masterpiece, bright, lively
-
-### Generation Workflows
-
-- Invoke offers a number of different workflows for interacting with models to produce images. Each is extremely powerful on its own, but together provide you an unparalleled way of producing high quality creative outputs that align with your vision.
- - **Text to Image:** The text to image tab focuses on the key workflow of using a prompt to generate a new image. It includes other features that help control the generation process as well.
- - **Image to Image:** With image to image, you provide an image as a reference (called the “initial image”), which provides more guidance around color and structure to the AI as it generates a new image. This is provided alongside the same features as Text to Image.
- - **Unified Canvas:** The Unified Canvas is an advanced AI-first image editing tool that is easy to use, but hard to master. Drag an image onto the canvas from your gallery in order to regenerate certain elements, edit content or colors (known as inpainting), or extend the image with an exceptional degree of consistency and clarity (called outpainting).
-
-### Improving Image Quality
-
-- Fine tuning your prompt - the more specific you are, the closer the image will turn out to what is in your head! Adding more details in the Positive Prompt or Negative Prompt can help add / remove pieces of your image to improve it - You can also use advanced techniques like upweighting and downweighting to control the influence of certain words. [Learn more here](https://invoke-ai.github.io/InvokeAI/features/PROMPTS/#prompt-syntax-features).
- - **Tip: If you’re seeing poor results, try adding the things you don’t like about the image to your negative prompt may help. E.g. distorted, low quality, unrealistic, etc.**
-- Explore different models - Other models can produce different results due to the data they’ve been trained on. Each model has specific language and settings it works best with; a model’s documentation is your friend here. Play around with some and see what works best for you!
-- Increasing Steps - The number of steps used controls how much time the model is given to produce an image, and depends on the “Scheduler” used. The schedule controls how each step is processed by the model. More steps tends to mean better results, but will take longer - We recommend at least 30 steps for most
-- Tweak and Iterate - Remember, it’s best to change one thing at a time so you know what is working and what isn't. Sometimes you just need to try a new image, and other times using a new prompt might be the ticket. For testing, consider turning off the “random” Seed - Using the same seed with the same settings will produce the same image, which makes it the perfect way to learn exactly what your changes are doing.
-- Explore Advanced Settings - InvokeAI has a full suite of tools available to allow you complete control over your image creation process - Check out our [docs if you want to learn more](https://invoke-ai.github.io/InvokeAI/features/).
-
-
-## Terms & Concepts
-
-If you're interested in learning more, check out [this presentation](https://docs.google.com/presentation/d/1IO78i8oEXFTZ5peuHHYkVF-Y3e2M6iM5tCnc-YBfcCM/edit?usp=sharing) from one of our maintainers (@lstein).
-
-### Stable Diffusion
-
-Stable Diffusion is deep learning, text-to-image model that is the foundation of the capabilities found in InvokeAI. Since the release of Stable Diffusion, there have been many subsequent models created based on Stable Diffusion that are designed to generate specific types of images.
-
-### Prompts
-
-Prompts provide the models directions on what to generate. As a general rule of thumb, the more detailed your prompt is, the better your result will be.
-
-### Models
-
-Models are the magic that power InvokeAI. These files represent the output of training a machine on understanding massive amounts of images - providing them with the capability to generate new images using just a text description of what you’d like to see. (Like Stable Diffusion!)
-
-Invoke offers a simple way to download several different models upon installation, but many more can be discovered online, including at https://models.invoke.ai
-
-Each model can produce a unique style of output, based on the images it was trained on - Try out different models to see which best fits your creative vision!
-
-- *Models that contain “inpainting” in the name are designed for use with the inpainting feature of the Unified Canvas*
-
-### Scheduler
-
-Schedulers guide the process of removing noise (de-noising) from data. They determine:
-
-1. The number of steps to take to remove the noise.
-2. Whether the steps are random (stochastic) or predictable (deterministic).
-3. The specific method (algorithm) used for de-noising.
-
-Experimenting with different schedulers is recommended as each will produce different outputs!
-
-### Steps
-
-The number of de-noising steps each generation through.
-
-Schedulers can be intricate and there's often a balance to strike between how quickly they can de-noise data and how well they can do it. It's typically advised to experiment with different schedulers to see which one gives the best results. There has been a lot written on the internet about different schedulers, as well as exploring what the right level of "steps" are for each. You can save generation time by reducing the number of steps used, but you'll want to make sure that you are satisfied with the quality of images produced!
-
-### Low-Rank Adaptations / LoRAs
-
-Low-Rank Adaptations (LoRAs) are like a smaller, more focused version of models, intended to focus on training a better understanding of how a specific character, style, or concept looks.
-
-### Textual Inversion Embeddings
-
-Textual Inversion Embeddings, like LoRAs, assist with more easily prompting for certain characters, styles, or concepts. However, embeddings are trained to update the relationship between a specific word (known as the “trigger”) and the intended output.
-
-### ControlNet
-
-ControlNets are neural network models that are able to extract key features from an existing image and use these features to guide the output of the image generation model.
-
-### VAE
-
-Variational auto-encoder (VAE) is a encode/decode model that translates the "latents" image produced during the image generation procees to the large pixel images that we see.
-
diff --git a/docs/img/favicon.ico b/docs/img/favicon.ico
deleted file mode 100644
index 16a72bebcbb..00000000000
Binary files a/docs/img/favicon.ico and /dev/null differ
diff --git a/docs/index.md b/docs/index.md
deleted file mode 100644
index d55d6a14f8f..00000000000
--- a/docs/index.md
+++ /dev/null
@@ -1,181 +0,0 @@
----
-title: Home
----
-
-
-
-
-
-
-
-
-
-
-
-
-[](https://github.com/invoke-ai/InvokeAI)
-
-[![discord badge]][discord link]
-
-[![latest release badge]][latest release link]
-[![github stars badge]][github stars link]
-[![github forks badge]][github forks link]
-
-
-
-[![github open issues badge]][github open issues link]
-[![github open prs badge]][github open prs link]
-
-[ci checks on dev badge]:
- https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/development?label=CI%20status%20on%20dev&cache=900&icon=github
-[ci checks on dev link]:
- https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Adevelopment
-[ci checks on main badge]:
- https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/main?label=CI%20status%20on%20main&cache=900&icon=github
-[ci checks on main link]:
- https://github.com/invoke-ai/InvokeAI/actions/workflows/test-invoke-conda.yml
-[discord badge]: https://flat.badgen.net/discord/members/ZmtBAhwWhy?icon=discord
-[discord link]: https://discord.gg/ZmtBAhwWhy
-[github forks badge]:
- https://flat.badgen.net/github/forks/invoke-ai/InvokeAI?icon=github
-[github forks link]:
- https://useful-forks.github.io/?repo=lstein%2Fstable-diffusion
-[github open issues badge]:
- https://flat.badgen.net/github/open-issues/invoke-ai/InvokeAI?icon=github
-[github open issues link]:
- https://github.com/invoke-ai/InvokeAI/issues?q=is%3Aissue+is%3Aopen
-[github open prs badge]:
- https://flat.badgen.net/github/open-prs/invoke-ai/InvokeAI?icon=github
-[github open prs link]:
- https://github.com/invoke-ai/InvokeAI/pulls?q=is%3Apr+is%3Aopen
-[github stars badge]:
- https://flat.badgen.net/github/stars/invoke-ai/InvokeAI?icon=github
-[github stars link]: https://github.com/invoke-ai/InvokeAI/stargazers
-
-[latest release badge]:
- https://flat.badgen.net/github/release/invoke-ai/InvokeAI/development?icon=github
-[latest release link]: https://github.com/invoke-ai/InvokeAI/releases
-
-
-
-InvokeAI is an
-implementation of Stable Diffusion, the open source text-to-image and
-image-to-image generator. It provides a streamlined process with various new
-features and options to aid the image generation process. It runs on Windows,
-Mac and Linux machines, and runs on GPU cards with as little as 4 GB of RAM.
-
-
Automatic Install & Updates
- -✅ The automatic install is the best way to run InvokeAI. Check out the [installation guide] to get started. - -⬆️ The same installer is also the best way to update InvokeAI - Simply rerun it for the same folder you installed to. - -The installation process simply manages installation for the core libraries & application dependencies that run Invoke. -Any models, images, or other assets in the Invoke root folder won't be affected by the installation process. - -Manual Install
- -If you are familiar with python and want more control over the packages that are installed, you can [install InvokeAI manually via PyPI]. - -Updates are managed by reinstalling the latest version through PyPi. - -Developer Install
- -If you want to contribute to InvokeAI, consult the [developer install guide]. - -Docker Install
- -This method is recommended for those familiar with running Docker containers. - -We offer a method for creating Docker containers containing InvokeAI and its dependencies. This method is recommended for individuals with experience with Docker containers and understand the pluses and minuses of a container-based install. - -See the [docker installation guide]. - -Other Installation Guides
- -- [PyPatchMatch](060_INSTALL_PATCHMATCH.md) -- [Installing Models](050_INSTALLING_MODELS.md) - -[install InvokeAI manually via PyPI]: 020_INSTALL_MANUAL.md -[developer install guide]: INSTALL_DEVELOPMENT.md -[docker installation guide]: 040_INSTALL_DOCKER.md -[installation guide]: 010_INSTALL_AUTOMATED.md -[FAQ]: ../help/FAQ.md -[discord]: discord.gg/invoke-ai -[create an issue]: https://github.com/invoke-ai/InvokeAI/issues -[installation requirements]: INSTALL_REQUIREMENTS.md diff --git a/docs/installation/INSTALL_DEVELOPMENT.md b/docs/installation/INSTALL_DEVELOPMENT.md deleted file mode 100644 index ead6b3bc8d6..00000000000 --- a/docs/installation/INSTALL_DEVELOPMENT.md +++ /dev/null @@ -1,37 +0,0 @@ -# Developer Install - -!!! warning - - InvokeAI uses a SQLite database. By running on `main`, you accept responsibility for your database. This - means making regular backups (especially before pulling) and/or fixing it yourself in the event that a - PR introduces a schema change. - - If you don't need persistent backend storage, you can use an ephemeral in-memory database by setting - `use_memory_db: true` in your `invokeai.yaml` file. You'll also want to set `scan_models_on_startup: true` - so that your models are registered on startup. - - If this is untenable, you should run the application via the official installer or a manual install of the - python package from PyPI. These releases will not break your database. - -If you have an interest in how InvokeAI works, or you would like to add features or bugfixes, you are encouraged to install the source code for InvokeAI. - -!!! info "Why do I need the frontend toolchain?" - - The repo doesn't contain a build of the frontend. You'll be responsible for rebuilding it (or running it in dev mode) to use the app, as described in the [frontend dev toolchain] docs. - -Installation
- -1. [Fork and clone] the [InvokeAI repo]. -1. Follow the [manual installation] docs to create a new virtual environment for the development install. - - Create a new folder outside the repo root for the installation and create the venv inside that folder. - - When installing the InvokeAI package, add `-e` to the command so you get an [editable install]. -1. Install the [frontend dev toolchain] and do a production build of the UI as described. -1. You can now run the app as described in the [manual installation] docs. - -As described in the [frontend dev toolchain] docs, you can run the UI using a dev server. If you do this, you won't need to continually rebuild the frontend. Instead, you run the dev server and use the app with the server URL it provides. - -[Fork and clone]: https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/working-with-forks/fork-a-repo -[InvokeAI repo]: https://github.com/invoke-ai/InvokeAI -[frontend dev toolchain]: ../contributing/frontend/OVERVIEW.md -[manual installation]: ./020_INSTALL_MANUAL.md -[editable install]: https://pip.pypa.io/en/latest/cli/pip_install/#cmdoption-e diff --git a/docs/installation/INSTALL_REQUIREMENTS.md b/docs/installation/INSTALL_REQUIREMENTS.md deleted file mode 100644 index 2279e7efb8a..00000000000 --- a/docs/installation/INSTALL_REQUIREMENTS.md +++ /dev/null @@ -1,181 +0,0 @@ -# Requirements - -## GPU - -!!! warning "Problematic Nvidia GPUs" - - We do not recommend these GPUs. They cannot operate with half precision, but have insufficient VRAM to generate 512x512 images at full precision. - - - NVIDIA 10xx series cards such as the 1080 TI - - GTX 1650 series cards - - GTX 1660 series cards - -Invoke runs best with a dedicated GPU, but will fall back to running on CPU, albeit much slower. You'll need a beefier GPU for SDXL. - -!!! example "Stable Diffusion 1.5" - - === "Nvidia" - - ``` - Any GPU with at least 4GB VRAM. - ``` - - === "AMD" - - ``` - Any GPU with at least 4GB VRAM. Linux only. - ``` - - === "Mac" - - ``` - Any Apple Silicon Mac with at least 8GB memory. - ``` - -!!! example "Stable Diffusion XL" - - === "Nvidia" - - ``` - Any GPU with at least 8GB VRAM. - ``` - - === "AMD" - - ``` - Any GPU with at least 16GB VRAM. Linux only. - ``` - - === "Mac" - - ``` - Any Apple Silicon Mac with at least 16GB memory. - ``` - -## RAM - -At least 12GB of RAM. - -## Disk - -SSDs will, of course, offer the best performance. - -The base application disk usage depends on the torch backend. - -!!! example "Disk" - - === "Nvidia (CUDA)" - - ``` - ~6.5GB - ``` - - === "AMD (ROCm)" - - ``` - ~12GB - ``` - - === "Mac (MPS)" - - ``` - ~3.5GB - ``` - -You'll need to set aside some space for images, depending on how much you generate. A couple GB is enough to get started. - -You'll need a good chunk of space for models. Even if you only install the most popular models and the usual support models (ControlNet, IP Adapter ,etc), you will quickly hit 50GB of models. - -!!! info "`tmpfs` on Linux" - - If your temporary directory is mounted as a `tmpfs`, ensure it has sufficient space. - -## Python - -Invoke requires python 3.10 or 3.11. If you don't already have one of these versions installed, we suggest installing 3.11, as it will be supported for longer. - -Check that your system has an up-to-date Python installed by running `python --version` in the terminal (Linux, macOS) or cmd/powershell (Windows). - -Installing Python (Windows)
- -- Install python 3.11 with [an official installer]. -- The installer includes an option to add python to your PATH. Be sure to enable this. If you missed it, re-run the installer, choose to modify an existing installation, and tick that checkbox. -- You may need to install [Microsoft Visual C++ Redistributable]. - -Installing Python (macOS)
- -- Install python 3.11 with [an official installer]. -- If model installs fail with a certificate error, you may need to run this command (changing the python version to match what you have installed): `/Applications/Python\ 3.10/Install\ Certificates.command` -- If you haven't already, you will need to install the XCode CLI Tools by running `xcode-select --install` in a terminal. - -Installing Python (Linux)
- -- Follow the [linux install instructions], being sure to install python 3.11. -- You'll need to install `libglib2.0-0` and `libgl1-mesa-glx` for OpenCV to work. For example, on a Debian system: `sudo apt update && sudo apt install -y libglib2.0-0 libgl1-mesa-glx` - -## Drivers - -If you have an Nvidia or AMD GPU, you may need to manually install drivers or other support packages for things to work well or at all. - -### Nvidia - -Run `nvidia-smi` on your system's command line to verify that drivers and CUDA are installed. If this command fails, or doesn't report versions, you will need to install drivers. - -Go to the [CUDA Toolkit Downloads] and carefully follow the instructions for your system to get everything installed. - -Confirm that `nvidia-smi` displays driver and CUDA versions after installation. - -#### Linux - via Nvidia Container Runtime - -An alternative to installing CUDA locally is to use the [Nvidia Container Runtime] to run the application in a container. - -#### Windows - Nvidia cuDNN DLLs - -An out-of-date cuDNN library can greatly hamper performance on 30-series and 40-series cards. Check with the community on discord to compare your `it/s` if you think you may need this fix. - -First, locate the destination for the DLL files and make a quick back up: - -1. Find your InvokeAI installation folder, e.g. `C:\Users\Username\InvokeAI\`. -1. Open the `.venv` folder, e.g. `C:\Users\Username\InvokeAI\.venv` (you may need to show hidden files to see it). -1. Navigate deeper to the `torch` package, e.g. `C:\Users\Username\InvokeAI\.venv\Lib\site-packages\torch`. -1. Copy the `lib` folder inside `torch` and back it up somewhere. - -Next, download and copy the updated cuDNN DLLs: - -1. Go to ->
->  ->
-> 
 -
---------------------------------
-### Average Images
-
-**Description:** This node takes in a collection of images of the same size and averages them as output. It converts everything to RGB mode first.
-
-**Node Link:** https://github.com/JPPhoto/average-images-node
-
---------------------------------
-### Clean Image Artifacts After Cut
-
-Description: Removes residual artifacts after an image is separated from its background.
-
-Node Link: https://github.com/VeyDlin/clean-artifact-after-cut-node
-
-View:
-
-
---------------------------------
-### Average Images
-
-**Description:** This node takes in a collection of images of the same size and averages them as output. It converts everything to RGB mode first.
-
-**Node Link:** https://github.com/JPPhoto/average-images-node
-
---------------------------------
-### Clean Image Artifacts After Cut
-
-Description: Removes residual artifacts after an image is separated from its background.
-
-Node Link: https://github.com/VeyDlin/clean-artifact-after-cut-node
-
-View:
- -
---------------------------------
-### Close Color Mask
-
-Description: Generates a mask for images based on a closely matching color, useful for color-based selections.
-
-Node Link: https://github.com/VeyDlin/close-color-mask-node
-
-View:
-
-
---------------------------------
-### Close Color Mask
-
-Description: Generates a mask for images based on a closely matching color, useful for color-based selections.
-
-Node Link: https://github.com/VeyDlin/close-color-mask-node
-
-View:
- -
---------------------------------
-### Clothing Mask
-
-Description: Employs a U2NET neural network trained for the segmentation of clothing items in images.
-
-Node Link: https://github.com/VeyDlin/clothing-mask-node
-
-View:
-
-
---------------------------------
-### Clothing Mask
-
-Description: Employs a U2NET neural network trained for the segmentation of clothing items in images.
-
-Node Link: https://github.com/VeyDlin/clothing-mask-node
-
-View:
- -
---------------------------------
-### Contrast Limited Adaptive Histogram Equalization
-
-Description: Enhances local image contrast using adaptive histogram equalization with contrast limiting.
-
-Node Link: https://github.com/VeyDlin/clahe-node
-
-View:
-
-
---------------------------------
-### Contrast Limited Adaptive Histogram Equalization
-
-Description: Enhances local image contrast using adaptive histogram equalization with contrast limiting.
-
-Node Link: https://github.com/VeyDlin/clahe-node
-
-View:
- -
---------------------------------
-### Depth Map from Wavefront OBJ
-
-**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
-
-To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
-
-**Node Link:** https://github.com/dwringer/depth-from-obj-node
-
-**Example Usage:**
-
-
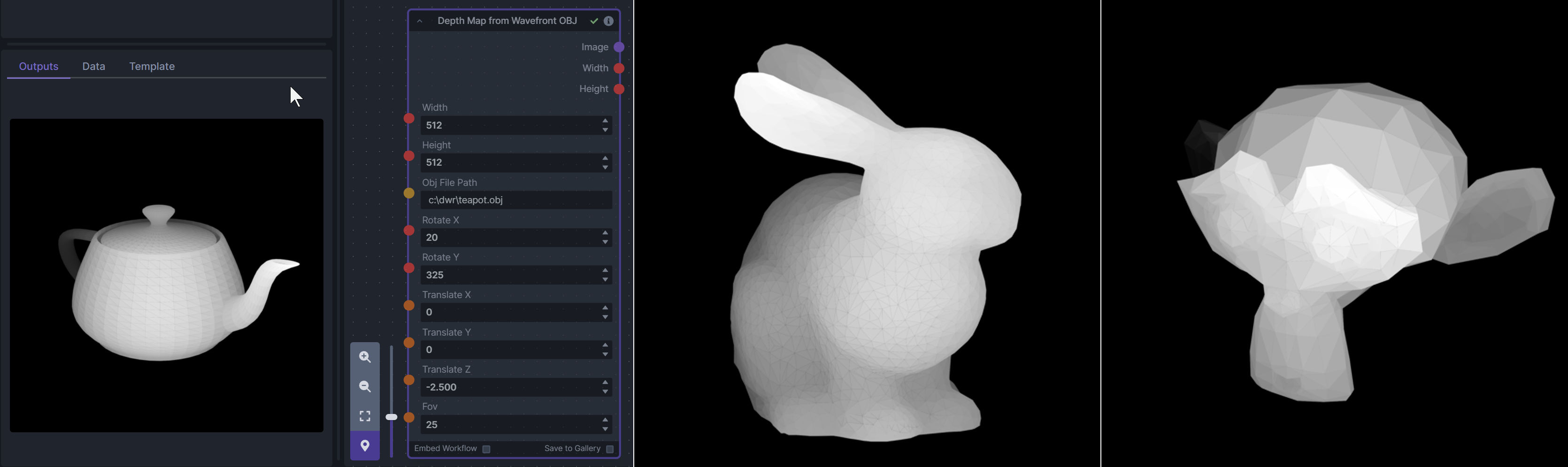
---------------------------------
-### Depth Map from Wavefront OBJ
-
-**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
-
-To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
-
-**Node Link:** https://github.com/dwringer/depth-from-obj-node
-
-**Example Usage:**
- -
---------------------------------
-### Film Grain
-
-**Description:** This node adds a film grain effect to the input image based on the weights, seeds, and blur radii parameters. It works with RGB input images only.
-
-**Node Link:** https://github.com/JPPhoto/film-grain-node
-
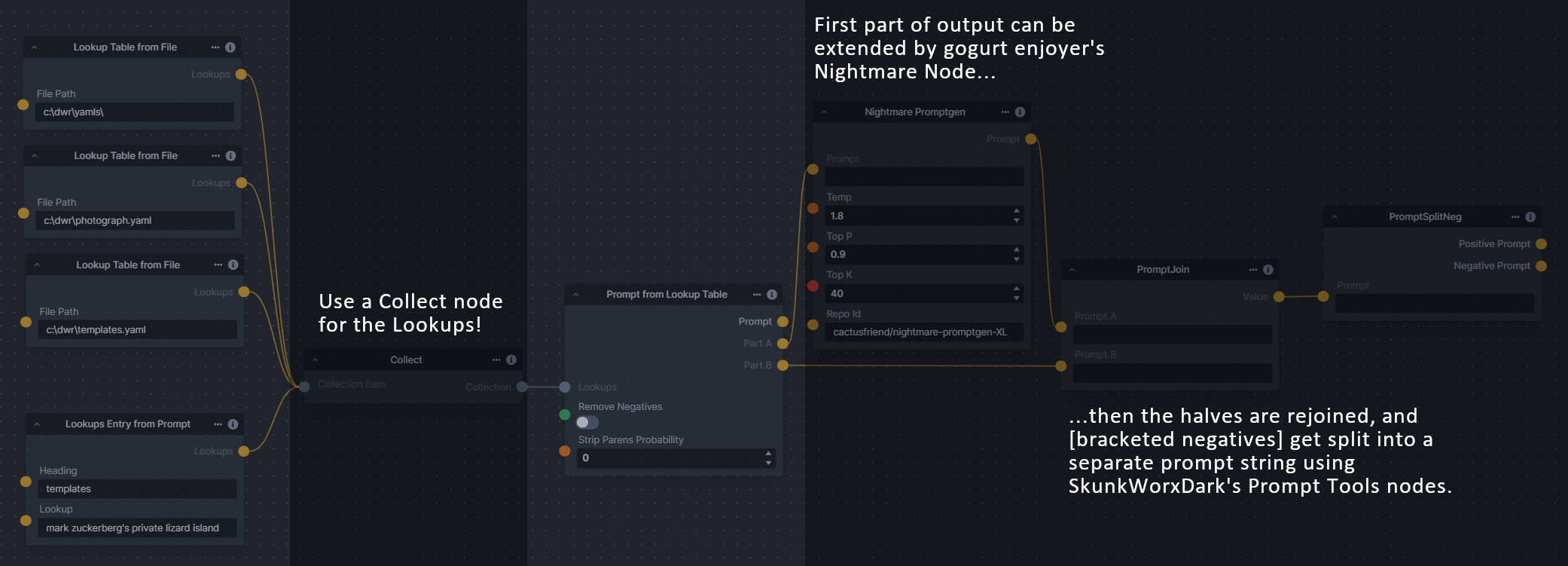
---------------------------------
-### Generative Grammar-Based Prompt Nodes
-
-**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
-
-This includes 3 Nodes:
-- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
-- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
-- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
-
-**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
-
-**Example Usage:**
-
-
---------------------------------
-### Film Grain
-
-**Description:** This node adds a film grain effect to the input image based on the weights, seeds, and blur radii parameters. It works with RGB input images only.
-
-**Node Link:** https://github.com/JPPhoto/film-grain-node
-
---------------------------------
-### Generative Grammar-Based Prompt Nodes
-
-**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
-
-This includes 3 Nodes:
-- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
-- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
-- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
-
-**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
-
-**Example Usage:**
- -
---------------------------------
-### GPT2RandomPromptMaker
-
-**Description:** A node for InvokeAI utilizes the GPT-2 language model to generate random prompts based on a provided seed and context.
-
-**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
-
-**Output Examples**
-
-Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
-
-
-
---------------------------------
-### GPT2RandomPromptMaker
-
-**Description:** A node for InvokeAI utilizes the GPT-2 language model to generate random prompts based on a provided seed and context.
-
-**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
-
-**Output Examples**
-
-Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
-
- -
- -
---------------------------------
-### Halftone
-
-**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
-
-**Node Link:** https://github.com/JPPhoto/halftone-node
-
-**Example**
-
-Input:
-
-
-
---------------------------------
-### Halftone
-
-**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
-
-**Node Link:** https://github.com/JPPhoto/halftone-node
-
-**Example**
-
-Input:
-
- -
---------------------------------
-
-### Image and Mask Composition Pack
-
-**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
-
-This includes 15 Nodes:
-
-- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
-- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
-- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
-- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
-- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
-- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
-- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
-- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
-- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
-- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
-- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
-- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
-- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
-- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
-- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
-
-**Node Link:** https://github.com/dwringer/composition-nodes
-
-
-
---------------------------------
-
-### Image and Mask Composition Pack
-
-**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
-
-This includes 15 Nodes:
-
-- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
-- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
-- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
-- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
-- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
-- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
-- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
-- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
-- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
-- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
-- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
-- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
-- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
-- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
-- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
-
-**Node Link:** https://github.com/dwringer/composition-nodes
-
- -
---------------------------------
-### Image Dominant Color
-
-Description: Identifies and extracts the dominant color from an image using k-means clustering.
-
-Node Link: https://github.com/VeyDlin/image-dominant-color-node
-
-View:
-
-
---------------------------------
-### Image Dominant Color
-
-Description: Identifies and extracts the dominant color from an image using k-means clustering.
-
-Node Link: https://github.com/VeyDlin/image-dominant-color-node
-
-View:
- -
---------------------------------
-### Image to Character Art Image Nodes
-
-**Description:** Group of nodes to convert an input image into ascii/unicode art Image
-
-**Node Link:** https://github.com/mickr777/imagetoasciiimage
-
-**Output Examples**
-
-
-
---------------------------------
-### Image to Character Art Image Nodes
-
-**Description:** Group of nodes to convert an input image into ascii/unicode art Image
-
-**Node Link:** https://github.com/mickr777/imagetoasciiimage
-
-**Output Examples**
-
-
 -
-
---------------------------------
-### Latent Upscale
-
-**Description:** This node uses a small (~2.4mb) model to upscale the latents used in a Stable Diffusion 1.5 or Stable Diffusion XL image generation, rather than the typical interpolation method, avoiding the traditional downsides of the latent upscale technique.
-
-**Node Link:** [https://github.com/gogurtenjoyer/latent-upscale](https://github.com/gogurtenjoyer/latent-upscale)
-
---------------------------------
-### Load Video Frame
-
-**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
-
-**Node Link:** https://github.com/helix4u/load_video_frame
-
-**Output Example:**
-
-
-
---------------------------------
-### Latent Upscale
-
-**Description:** This node uses a small (~2.4mb) model to upscale the latents used in a Stable Diffusion 1.5 or Stable Diffusion XL image generation, rather than the typical interpolation method, avoiding the traditional downsides of the latent upscale technique.
-
-**Node Link:** [https://github.com/gogurtenjoyer/latent-upscale](https://github.com/gogurtenjoyer/latent-upscale)
-
---------------------------------
-### Load Video Frame
-
-**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
-
-**Node Link:** https://github.com/helix4u/load_video_frame
-
-**Output Example:**
- -
---------------------------------
-### Make 3D
-
-**Description:** Create compelling 3D stereo images from 2D originals.
-
-**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
-
-**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
-
-**Output Examples**
-
-
-
---------------------------------
-### Make 3D
-
-**Description:** Create compelling 3D stereo images from 2D originals.
-
-**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
-
-**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
-
-**Output Examples**
-
- -
- -
---------------------------------
-### Mask Operations
-
-Description: Offers logical operations (OR, SUB, AND) for combining and manipulating image masks.
-
-Node Link: https://github.com/VeyDlin/mask-operations-node
-
-View:
-
-
---------------------------------
-### Mask Operations
-
-Description: Offers logical operations (OR, SUB, AND) for combining and manipulating image masks.
-
-Node Link: https://github.com/VeyDlin/mask-operations-node
-
-View:
-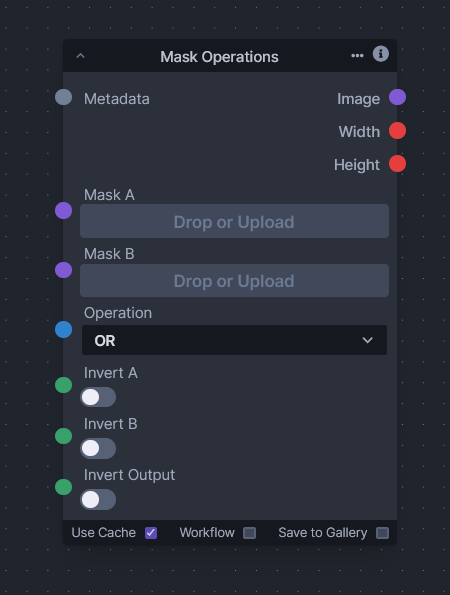 -
---------------------------------
-### Match Histogram
-
-**Description:** An InvokeAI node to match a histogram from one image to another. This is a bit like the `color correct` node in the main InvokeAI but this works in the YCbCr colourspace and can handle images of different sizes. Also does not require a mask input.
-- Option to only transfer luminance channel.
-- Option to save output as grayscale
-
-A good use case for this node is to normalize the colors of an image that has been through the tiled scaling workflow of my XYGrid Nodes.
-
-See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
-
-**Node Link:** https://github.com/skunkworxdark/match_histogram
-
-**Output Examples**
-
-
-
---------------------------------
-### Match Histogram
-
-**Description:** An InvokeAI node to match a histogram from one image to another. This is a bit like the `color correct` node in the main InvokeAI but this works in the YCbCr colourspace and can handle images of different sizes. Also does not require a mask input.
-- Option to only transfer luminance channel.
-- Option to save output as grayscale
-
-A good use case for this node is to normalize the colors of an image that has been through the tiled scaling workflow of my XYGrid Nodes.
-
-See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
-
-**Node Link:** https://github.com/skunkworxdark/match_histogram
-
-**Output Examples**
-
- -
---------------------------------
-### Nightmare Promptgen
-
-**Description:** Nightmare Prompt Generator - Uses a local text generation model to create unique imaginative (but usually nightmarish) prompts for InvokeAI. By default, it allows you to choose from some gpt-neo models I finetuned on over 2500 of my own InvokeAI prompts in Compel format, but you're able to add your own, as well. Offers support for replacing any troublesome words with a random choice from list you can also define.
-
-**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
-
---------------------------------
-### Oobabooga
-
-**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
-
-**Link:** https://github.com/sammyf/oobabooga-node
-
-**Example:**
-
-"describe a new mystical creature in its natural environment"
-
-*can return*
-
-"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
-As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
-
-
-
---------------------------------
-### Nightmare Promptgen
-
-**Description:** Nightmare Prompt Generator - Uses a local text generation model to create unique imaginative (but usually nightmarish) prompts for InvokeAI. By default, it allows you to choose from some gpt-neo models I finetuned on over 2500 of my own InvokeAI prompts in Compel format, but you're able to add your own, as well. Offers support for replacing any troublesome words with a random choice from list you can also define.
-
-**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
-
---------------------------------
-### Oobabooga
-
-**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
-
-**Link:** https://github.com/sammyf/oobabooga-node
-
-**Example:**
-
-"describe a new mystical creature in its natural environment"
-
-*can return*
-
-"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
-As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
-
--- `Prompt Join` -> `String Join` -- `Prompt Join Three` -> `String Join Three` -- `Prompt Replace` -> `String Replace` -- `Prompt Split Neg` -> `String Split Neg` - - -See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md - -**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes - -**Workflow Examples** - -
 -
---------------------------------
-### Remote Image
-
-**Description:** This is a pack of nodes to interoperate with other services, be they public websites or bespoke local servers. The pack consists of these nodes:
-
-- *Load Remote Image* - Lets you load remote images such as a realtime webcam image, an image of the day, or dynamically created images.
-- *Post Image to Remote Server* - Lets you upload an image to a remote server using an HTTP POST request, eg for storage, display or further processing.
-
-**Node Link:** https://github.com/fieldOfView/InvokeAI-remote_image
-
---------------------------------
-
-### BriaAI Remove Background
-
-**Description**: Implements one click background removal with BriaAI's new version 1.4 model which seems to be be producing better results than any other previous background removal tool.
-
-**Node Link:** https://github.com/blessedcoolant/invoke_bria_rmbg
-
-**View**
-
-
---------------------------------
-### Remote Image
-
-**Description:** This is a pack of nodes to interoperate with other services, be they public websites or bespoke local servers. The pack consists of these nodes:
-
-- *Load Remote Image* - Lets you load remote images such as a realtime webcam image, an image of the day, or dynamically created images.
-- *Post Image to Remote Server* - Lets you upload an image to a remote server using an HTTP POST request, eg for storage, display or further processing.
-
-**Node Link:** https://github.com/fieldOfView/InvokeAI-remote_image
-
---------------------------------
-
-### BriaAI Remove Background
-
-**Description**: Implements one click background removal with BriaAI's new version 1.4 model which seems to be be producing better results than any other previous background removal tool.
-
-**Node Link:** https://github.com/blessedcoolant/invoke_bria_rmbg
-
-**View**
- -
---------------------------------
-### Remove Background
-
-Description: An integration of the rembg package to remove backgrounds from images using multiple U2NET models.
-
-Node Link: https://github.com/VeyDlin/remove-background-node
-
-View:
-
-
---------------------------------
-### Remove Background
-
-Description: An integration of the rembg package to remove backgrounds from images using multiple U2NET models.
-
-Node Link: https://github.com/VeyDlin/remove-background-node
-
-View:
-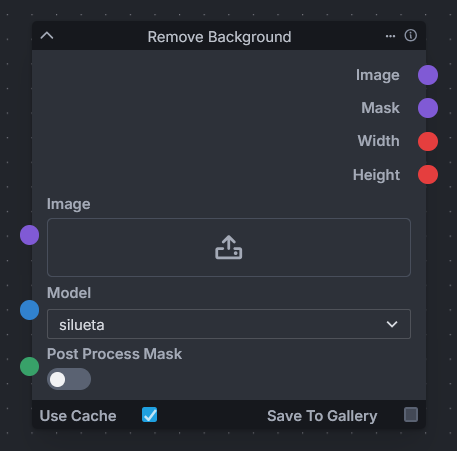 -
---------------------------------
-### Retroize
-
-**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
-
-**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
-
-**Retroize Output Examples**
-
-
-
---------------------------------
-### Retroize
-
-**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
-
-**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
-
-**Retroize Output Examples**
-
- -
-
---------------------------------
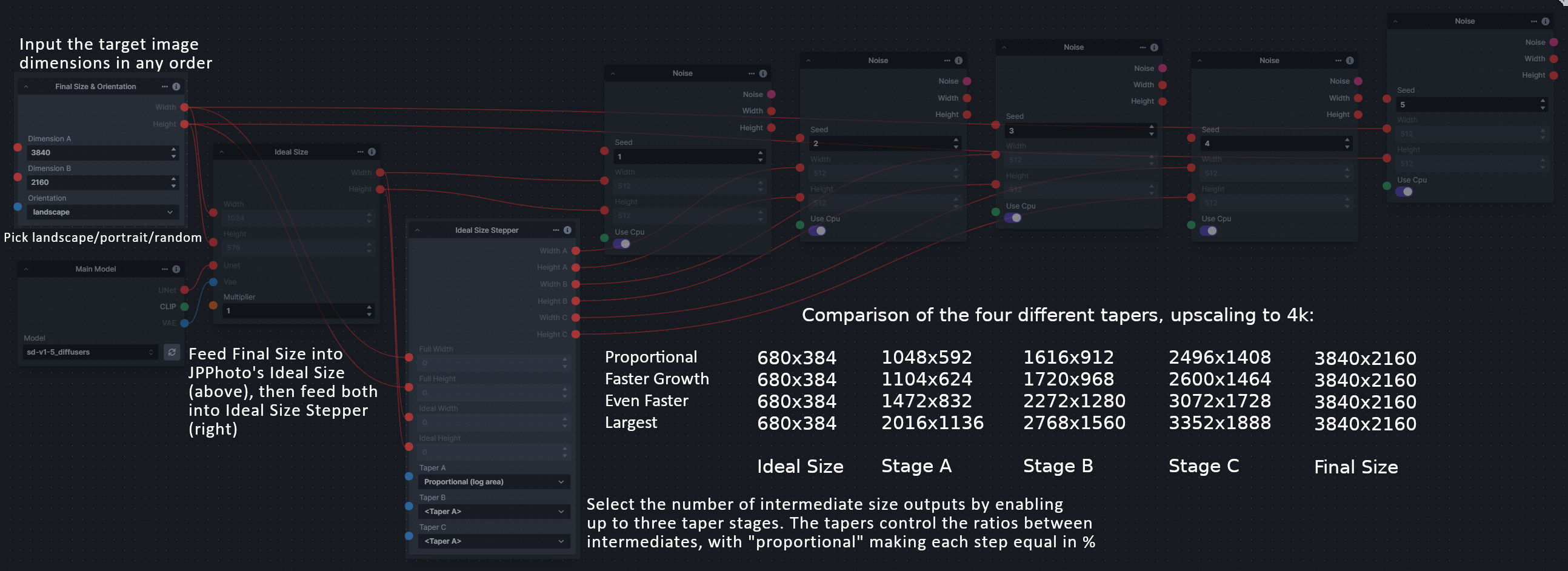
-### Size Stepper Nodes
-
-**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
-
-A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
-
-**Node Link:** https://github.com/dwringer/size-stepper-nodes
-
-**Example Usage:**
-
-
-
---------------------------------
-### Size Stepper Nodes
-
-**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
-
-A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
-
-**Node Link:** https://github.com/dwringer/size-stepper-nodes
-
-**Example Usage:**
- -
---------------------------------
-### Text font to Image
-
-**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
-
-**Node Link:** https://github.com/mickr777/textfontimage
-
-**Output Examples**
-
-
-
---------------------------------
-### Text font to Image
-
-**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
-
-**Node Link:** https://github.com/mickr777/textfontimage
-
-**Output Examples**
-
- -
-
---------------------------------
-### Example Node Template
-
-**Description:** This node allows you to do super cool things with InvokeAI.
-
-**Node Link:** https://github.com/invoke-ai/InvokeAI/blob/main/invokeai/app/invocations/prompt.py
-
-**Example Workflow:** https://github.com/invoke-ai/InvokeAI/blob/docs/main/docs/workflows/Prompt_from_File.json
-
-**Output Examples**
-
-
-
-
---------------------------------
-### Example Node Template
-
-**Description:** This node allows you to do super cool things with InvokeAI.
-
-**Node Link:** https://github.com/invoke-ai/InvokeAI/blob/main/invokeai/app/invocations/prompt.py
-
-**Example Workflow:** https://github.com/invoke-ai/InvokeAI/blob/docs/main/docs/workflows/Prompt_from_File.json
-
-**Output Examples**
-
- -
-
-## Disclaimer
-
-The nodes linked have been developed and contributed by members of the Invoke AI community. While we strive to ensure the quality and safety of these contributions, we do not guarantee the reliability or security of the nodes. If you have issues or concerns with any of the nodes below, please raise it on GitHub or in the Discord.
-
-
-## Help
-If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
-
diff --git a/docs/nodes/contributingNodes.md b/docs/nodes/contributingNodes.md
deleted file mode 100644
index 7a30c8aeb0f..00000000000
--- a/docs/nodes/contributingNodes.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Contributing Nodes
-
-To learn about the specifics of creating a new node, please visit our [Node creation documentation](../contributing/INVOCATIONS.md).
-
-Once you’ve created a node and confirmed that it behaves as expected locally, follow these steps:
-
-- Make sure the node is contained in a new Python (.py) file. Preferably, the node is in a repo with a README detailing the nodes usage & examples to help others more easily use your node. Including the tag "invokeai-node" in your repository's README can also help other users find it more easily.
-- Submit a pull request with a link to your node(s) repo in GitHub against the `main` branch to add the node to the [Community Nodes](communityNodes.md) list
- - Make sure you are following the template below and have provided all relevant details about the node and what it does. Example output images and workflows are very helpful for other users looking to use your node.
-- A maintainer will review the pull request and node. If the node is aligned with the direction of the project, you may be asked for permission to include it in the core project.
-
-### Community Node Template
-
-```markdown
---------------------------------
-### Super Cool Node Template
-
-**Description:** This node allows you to do super cool things with InvokeAI.
-
-**Node Link:** https://github.com/invoke-ai/InvokeAI/fake_node.py
-
-**Example Node Graph:** https://github.com/invoke-ai/InvokeAI/fake_node_graph.json
-
-**Output Examples**
-
-
-```
diff --git a/docs/nodes/defaultNodes.md b/docs/nodes/defaultNodes.md
deleted file mode 100644
index b78c9af9010..00000000000
--- a/docs/nodes/defaultNodes.md
+++ /dev/null
@@ -1,109 +0,0 @@
-# List of Default Nodes
-
-The table below contains a list of the default nodes shipped with InvokeAI and
-their descriptions.
-
-| Node
-
-
-## Disclaimer
-
-The nodes linked have been developed and contributed by members of the Invoke AI community. While we strive to ensure the quality and safety of these contributions, we do not guarantee the reliability or security of the nodes. If you have issues or concerns with any of the nodes below, please raise it on GitHub or in the Discord.
-
-
-## Help
-If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
-
diff --git a/docs/nodes/contributingNodes.md b/docs/nodes/contributingNodes.md
deleted file mode 100644
index 7a30c8aeb0f..00000000000
--- a/docs/nodes/contributingNodes.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Contributing Nodes
-
-To learn about the specifics of creating a new node, please visit our [Node creation documentation](../contributing/INVOCATIONS.md).
-
-Once you’ve created a node and confirmed that it behaves as expected locally, follow these steps:
-
-- Make sure the node is contained in a new Python (.py) file. Preferably, the node is in a repo with a README detailing the nodes usage & examples to help others more easily use your node. Including the tag "invokeai-node" in your repository's README can also help other users find it more easily.
-- Submit a pull request with a link to your node(s) repo in GitHub against the `main` branch to add the node to the [Community Nodes](communityNodes.md) list
- - Make sure you are following the template below and have provided all relevant details about the node and what it does. Example output images and workflows are very helpful for other users looking to use your node.
-- A maintainer will review the pull request and node. If the node is aligned with the direction of the project, you may be asked for permission to include it in the core project.
-
-### Community Node Template
-
-```markdown
---------------------------------
-### Super Cool Node Template
-
-**Description:** This node allows you to do super cool things with InvokeAI.
-
-**Node Link:** https://github.com/invoke-ai/InvokeAI/fake_node.py
-
-**Example Node Graph:** https://github.com/invoke-ai/InvokeAI/fake_node_graph.json
-
-**Output Examples**
-
-
-```
diff --git a/docs/nodes/defaultNodes.md b/docs/nodes/defaultNodes.md
deleted file mode 100644
index b78c9af9010..00000000000
--- a/docs/nodes/defaultNodes.md
+++ /dev/null
@@ -1,109 +0,0 @@
-# List of Default Nodes
-
-The table below contains a list of the default nodes shipped with InvokeAI and
-their descriptions.
-
-| Node -[Robin Rombach](https://github.com/rromb)\*, -[Andreas Blattmann](https://github.com/ablattmann)\*, -[Dominik Lorenz](https://github.com/qp-qp)\, -[Patrick Esser](https://github.com/pesser), -[Björn Ommer](https://hci.iwr.uni-heidelberg.de/Staff/bommer)
- -## **CVPR '22 Oral** - -which is available on [GitHub](https://github.com/CompVis/latent-diffusion). PDF -at [arXiv](https://arxiv.org/abs/2112.10752). Please also visit our -[Project page](https://ommer-lab.com/research/latent-diffusion-models/). - - -[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion -model. Thanks to a generous compute donation from -[Stability AI](https://stability.ai/) and support from -[LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on -512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) -database. Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487), this -model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text -prompts. With its 860M UNet and 123M text encoder, the model is relatively -lightweight and runs on a GPU with at least 10GB VRAM. See -[this section](#stable-diffusion-v1) below and the -[model card](https://huggingface.co/CompVis/stable-diffusion). - -## Requirements - -A suitable [conda](https://conda.io/) environment named `ldm` can be created and -activated with: - -``` -conda env create -conda activate ldm -``` - -Note that the first line may be abbreviated `conda env create`, since conda will -look for `environment.yml` by default. - -You can also update an existing -[latent diffusion](https://github.com/CompVis/latent-diffusion) environment by -running - -```bash -conda install pytorch torchvision -c pytorch -pip install transformers==4.19.2 -pip install -e . -``` - -## Stable Diffusion v1 - -Stable Diffusion v1 refers to a specific configuration of the model architecture -that uses a downsampling-factor 8 autoencoder with an 860M UNet and CLIP -ViT-L/14 text encoder for the diffusion model. The model was pretrained on -256x256 images and then finetuned on 512x512 images. - -\*Note: Stable Diffusion v1 is a general text-to-image diffusion model and -therefore mirrors biases and (mis-)conceptions that are present in its training -data. Details on the training procedure and data, as well as the intended use of -the model can be found in the corresponding -[model card](https://huggingface.co/CompVis/stable-diffusion). Research into the -safe deployment of general text-to-image models is an ongoing effort. To prevent -misuse and harm, we currently provide access to the checkpoints only for -[academic research purposes upon request](https://stability.ai/academia-access-form). -**This is an experiment in safe and community-driven publication of a capable -and general text-to-image model. We are working on a public release with a more -permissive license that also incorporates ethical considerations.\*** - -[Request access to Stable Diffusion v1 checkpoints for academic research](https://stability.ai/academia-access-form) - -### Weights - -We currently provide three checkpoints, `sd-v1-1.ckpt`, `sd-v1-2.ckpt` and -`sd-v1-3.ckpt`, which were trained as follows, - -- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on - [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en). 194k steps at - resolution `512x512` on - [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) - (170M examples from LAION-5B with resolution `>= 1024x1024`). -- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`. 515k steps at resolution - `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en, filtered to - images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, - and an estimated watermark probability `< 0.5`. The watermark estimate is from - the LAION-5B metadata, the aesthetics score is estimated using an - [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)). -- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution - `512x512` on "laion-improved-aesthetics" and 10\% dropping of the - text-conditioning to improve - [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598). - -Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0, -5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling steps show the relative improvements of -the checkpoints:  - -### Text-to-Image with Stable Diffusion - - - - -Stable Diffusion is a latent diffusion model conditioned on the (non-pooled) -text embeddings of a CLIP ViT-L/14 text encoder. - -#### Sampling Script - -After [obtaining the weights](#weights), link them - -``` -mkdir -p models/ldm/stable-diffusion-v1/ -ln -s
+
diff --git a/docs/src/content/docs/configuration/fp8-storage.mdx b/docs/src/content/docs/configuration/fp8-storage.mdx
new file mode 100644
index 00000000000..799821b079e
--- /dev/null
+++ b/docs/src/content/docs/configuration/fp8-storage.mdx
@@ -0,0 +1,128 @@
+---
+title: FP8 Storage
+sidebar:
+ order: 3
+---
+
+import { Steps } from '@astrojs/starlight/components';
+
+FP8 Storage cuts a model's VRAM footprint roughly in half by keeping weights on the GPU in 8-bit floating-point format (`float8_e4m3fn`). During inference, each layer's weights are cast on-the-fly back up to the compute precision (FP16/BF16), then cast back to FP8 after the forward pass — so quality is largely preserved.
+
+It pairs well with [Low-VRAM mode](/configuration/low-vram-mode/): low-VRAM mode streams layers between RAM and VRAM, while FP8 Storage shrinks the layers themselves.
+
+:::caution[For full precision models only]
+FP8 Storage only applies to **full precision** checkpoints (FP16 / BF16 / FP32). It is **silently a no-op** for already-quantized formats — **GGUF**, **NF4**, and **int8** checkpoints carry their own storage precision and the loader returns a different module type that the FP8 layer cast does not touch. If your model is already quantized, the toggle has no effect; use the full-precision variant of the model if you want to enable FP8 Storage.
+:::
+
+## Requirements
+
+- **Nvidia GPU on Windows or Linux.** FP8 Storage uses CUDA tensor types and is silently disabled on CPU and MPS.
+- **CUDA 12.x and recent PyTorch.** The `float8_e4m3fn` dtype was added in PyTorch 2.1 — InvokeAI's bundled versions satisfy this.
+
+There is no hardware requirement for FP8 *compute* — InvokeAI casts back to FP16/BF16 for math. This means FP8 Storage works on GPUs that do not natively support FP8 matmul (e.g. RTX 30-series), at a small per-step throughput cost.
+
+## Hardware support tiers
+
+InvokeAI's FP8 path stores weights in FP8 and casts them back to BF16/FP16 on each forward pass via its own `register_forward_pre_hook` / `register_forward_hook` wrappers (the same skip list as diffusers' `apply_layerwise_casting`, but applied to every `nn.Module` — including diffusers `ModelMixin` subclasses — so it composes correctly with InvokeAI's `CustomLinear` and partial loading). The practical benefit of toggling FP8 Storage depends on what your GPU can do natively. There are three tiers:
+
+### RTX 30-series and older Ampere workstation cards — VRAM win only
+
+The toggle works as advertised: the UNet / transformer drops by roughly 50% on the GPU. Per-step latency is the same or marginally slower because every forward pass adds an FP8 → BF16 cast on entry and a BF16 → FP8 cast on exit. This is the **largest target group**: 3090 owners squeezing FLUX into 24 GB benefit the most.
+
+### RTX 40-series, RTX 50-series, and Hopper — VRAM win today, compute win possible later
+
+These GPUs have native FP8 tensor cores. The toggle still buys you the same ~50% VRAM reduction today, because the forward pass still runs in BF16 — the hook casts weights back up to compute precision before each layer. If InvokeAI later wires up a true FP8 matmul path (e.g. via `torchao`), the same toggle will *also* unlock compute speedups on this hardware. Until then, treat the benefit as "VRAM only, same as Ampere".
+
+### Older CUDA cards — still a VRAM win
+
+`float8_e4m3fn` is a pure storage dtype in PyTorch and works on any CUDA device, so pre-Ampere cards (GTX 16-series, RTX 20-series, etc.) get the same ~50% VRAM reduction as Ampere. There are no native FP8 tensor cores on these GPUs, so the throughput trade-off is the same as on the 30-series: cast in, compute in BF16/FP16, cast back out.
+
+### MPS and CPU — no-op
+
+FP8 Storage is silently disabled on anything that is not CUDA. On CPU PyTorch *technically* supports FP8 dtypes, but the cast operations are software-emulated and end up costing more than the memory savings buy back, so InvokeAI gates the entire path on `device.type == "cuda"`. If you toggle it on CPU or MPS, the loader skips the cast and returns the model unchanged with no log line.
+
+## Enabling FP8 Storage
+
+FP8 Storage is a **per-model setting**, configured from the Model Manager:
+
+"I am running Windows under WSL2, and am seeing a 'no such file or directory' error."
+ + Your `docker-entrypoint.sh` might have has Windows (CRLF) line endings, depending how you cloned the repository. + To solve this, change the line endings in the `docker-entrypoint.sh` file to `LF`. You can do this in VSCode + (`Ctrl+P` and search for "line endings"), or by using the `dos2unix` utility in WSL. + Finally, you may delete `docker-entrypoint.sh` followed by `git pull; git checkout docker/docker-entrypoint.sh` + to reset the file to its most recent version. + For more information on this issue, see [Docker Desktop documentation](https://docs.docker.com/desktop/troubleshoot/topics/#avoid-unexpected-syntax-errors-use-unix-style-line-endings-for-files-in-containers) + + ->
->  ->
-> 
 +
+---
+
+### Average Images
+
+**Description:** This node takes in a collection of images of the same size and averages them as output. It converts everything to RGB mode first.
+
+**Node Link:** https://github.com/JPPhoto/average-images-node
+
+---
+
+### BiRefNet Background Removal
+
+**Description:** Remove image backgrounds using BiRefNet (Bilateral Reference Network), a high-quality segmentation model. Supports multiple model variants including standard, high-resolution, matting, portrait, and specialized models for different use cases.
+
+**Node Link:** https://github.com/veeliks/invoke_birefnet
+
+**Output Examples**
+
+
+
+---
+
+### Average Images
+
+**Description:** This node takes in a collection of images of the same size and averages them as output. It converts everything to RGB mode first.
+
+**Node Link:** https://github.com/JPPhoto/average-images-node
+
+---
+
+### BiRefNet Background Removal
+
+**Description:** Remove image backgrounds using BiRefNet (Bilateral Reference Network), a high-quality segmentation model. Supports multiple model variants including standard, high-resolution, matting, portrait, and specialized models for different use cases.
+
+**Node Link:** https://github.com/veeliks/invoke_birefnet
+
+**Output Examples**
+
+ +
+  +
+
+---
+
+### Close Color Mask
+
+Description: Generates a mask for images based on a closely matching color, useful for color-based selections.
+
+Node Link: https://github.com/VeyDlin/close-color-mask-node
+
+View:
+
+
+
+---
+
+### Clothing Mask
+
+Description: Employs a U2NET neural network trained for the segmentation of clothing items in images.
+
+Node Link: https://github.com/VeyDlin/clothing-mask-node
+
+View:
+
+
+
+---
+
+### Contrast Limited Adaptive Histogram Equalization
+
+Description: Enhances local image contrast using adaptive histogram equalization with contrast limiting.
+
+Node Link: https://github.com/VeyDlin/clahe-node
+
+View:
+
+
+
+---
+
+### Curves
+
+**Description:** Adjust an image's curve based on a user-defined string.
+
+**Node Link:** https://github.com/JPPhoto/curves-node
+
+---
+
+### Depth Map from Wavefront OBJ
+
+**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
+
+To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
+
+**Node Link:** https://github.com/dwringer/depth-from-obj-node
+
+**Example Usage:**
+
+
+
+---
+
+### Enhance Detail
+
+**Description:** A single node that can enhance the detail in an image. Increase or decrease details in an image using a guided filter (as opposed to the typical Gaussian blur used by most sharpening filters.) Based on the `Enhance Detail` ComfyUI node from https://github.com/spacepxl/ComfyUI-Image-Filters
+
+**Node Link:** https://github.com/skunkworxdark/enhance-detail-node
+
+**Example Usage:**
+
+
+
+
+---
+
+### Close Color Mask
+
+Description: Generates a mask for images based on a closely matching color, useful for color-based selections.
+
+Node Link: https://github.com/VeyDlin/close-color-mask-node
+
+View:
+
+
+
+---
+
+### Clothing Mask
+
+Description: Employs a U2NET neural network trained for the segmentation of clothing items in images.
+
+Node Link: https://github.com/VeyDlin/clothing-mask-node
+
+View:
+
+
+
+---
+
+### Contrast Limited Adaptive Histogram Equalization
+
+Description: Enhances local image contrast using adaptive histogram equalization with contrast limiting.
+
+Node Link: https://github.com/VeyDlin/clahe-node
+
+View:
+
+
+
+---
+
+### Curves
+
+**Description:** Adjust an image's curve based on a user-defined string.
+
+**Node Link:** https://github.com/JPPhoto/curves-node
+
+---
+
+### Depth Map from Wavefront OBJ
+
+**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
+
+To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
+
+**Node Link:** https://github.com/dwringer/depth-from-obj-node
+
+**Example Usage:**
+
+
+
+---
+
+### Enhance Detail
+
+**Description:** A single node that can enhance the detail in an image. Increase or decrease details in an image using a guided filter (as opposed to the typical Gaussian blur used by most sharpening filters.) Based on the `Enhance Detail` ComfyUI node from https://github.com/spacepxl/ComfyUI-Image-Filters
+
+**Node Link:** https://github.com/skunkworxdark/enhance-detail-node
+
+**Example Usage:**
+
+ +
+---
+
+### Film Grain
+
+**Description:** This node adds a film grain effect to the input image based on the weights, seeds, and blur radii parameters. It works with RGB input images only.
+
+**Node Link:** https://github.com/JPPhoto/film-grain-node
+
+---
+
+### Flip Pose
+
+**Description:** This node will flip an openpose image horizontally, recoloring it to make sure that it isn't facing the wrong direction. Note that it does not work with openpose hands.
+
+**Node Link:** https://github.com/JPPhoto/flip-pose-node
+
+---
+
+### Flux Ideal Size
+
+**Description:** This node returns an ideal size to use for the first stage of a Flux image generation pipeline. Generating at the right size helps limit duplication and odd subject placement.
+
+**Node Link:** https://github.com/JPPhoto/flux-ideal-size
+
+---
+
+### Generative Grammar-Based Prompt Nodes
+
+**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
+
+This includes 3 Nodes:
+- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
+- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
+- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
+
+**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
+
+**Example Usage:**
+
+
+
+---
+
+### GPT2RandomPromptMaker
+
+**Description:** A node for InvokeAI utilizes the GPT-2 language model to generate random prompts based on a provided seed and context.
+
+**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
+
+**Output Examples**
+
+Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
+
+
+
+
+---
+
+### Halftone
+
+**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
+
+**Node Link:** https://github.com/JPPhoto/halftone-node
+
+**Example**
+
+Input:
+
+
+
+---
+
+### Image and Mask Composition Pack
+
+**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
+
+This includes 15 Nodes:
+
+- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
+- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
+- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
+- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
+- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
+- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
+- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
+- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
+- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
+- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
+- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
+- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
+- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
+- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
+- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
+
+**Node Link:** https://github.com/dwringer/composition-nodes
+
+
+
+---
+
+### Image Dominant Color
+
+Description: Identifies and extracts the dominant color from an image using k-means clustering.
+
+Node Link: https://github.com/VeyDlin/image-dominant-color-node
+
+View:
+
+
+
+---
+
+### Image Export
+
+**Description:** Export images in multiple formats (AVIF, JPEG, PNG, TIFF, WebP) with format-specific compression and quality options.
+
+**Node Link:** https://github.com/veeliks/invoke_image_export
+
+**Nodes:**
+
+
+
+---
+
+### Film Grain
+
+**Description:** This node adds a film grain effect to the input image based on the weights, seeds, and blur radii parameters. It works with RGB input images only.
+
+**Node Link:** https://github.com/JPPhoto/film-grain-node
+
+---
+
+### Flip Pose
+
+**Description:** This node will flip an openpose image horizontally, recoloring it to make sure that it isn't facing the wrong direction. Note that it does not work with openpose hands.
+
+**Node Link:** https://github.com/JPPhoto/flip-pose-node
+
+---
+
+### Flux Ideal Size
+
+**Description:** This node returns an ideal size to use for the first stage of a Flux image generation pipeline. Generating at the right size helps limit duplication and odd subject placement.
+
+**Node Link:** https://github.com/JPPhoto/flux-ideal-size
+
+---
+
+### Generative Grammar-Based Prompt Nodes
+
+**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
+
+This includes 3 Nodes:
+- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
+- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
+- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
+
+**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
+
+**Example Usage:**
+
+
+
+---
+
+### GPT2RandomPromptMaker
+
+**Description:** A node for InvokeAI utilizes the GPT-2 language model to generate random prompts based on a provided seed and context.
+
+**Node Link:** https://github.com/mickr777/GPT2RandomPromptMaker
+
+**Output Examples**
+
+Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
+
+
+
+
+---
+
+### Halftone
+
+**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
+
+**Node Link:** https://github.com/JPPhoto/halftone-node
+
+**Example**
+
+Input:
+
+
+
+---
+
+### Image and Mask Composition Pack
+
+**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
+
+This includes 15 Nodes:
+
+- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
+- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
+- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
+- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
+- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
+- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
+- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
+- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
+- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
+- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
+- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
+- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
+- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
+- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
+- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
+
+**Node Link:** https://github.com/dwringer/composition-nodes
+
+
+
+---
+
+### Image Dominant Color
+
+Description: Identifies and extracts the dominant color from an image using k-means clustering.
+
+Node Link: https://github.com/VeyDlin/image-dominant-color-node
+
+View:
+
+
+
+---
+
+### Image Export
+
+**Description:** Export images in multiple formats (AVIF, JPEG, PNG, TIFF, WebP) with format-specific compression and quality options.
+
+**Node Link:** https://github.com/veeliks/invoke_image_export
+
+**Nodes:**
+
+ +
+  +
+  +
+  +
+  +
+
+
+
+---
+
+### Latent Upscale
+
+**Description:** This node uses a small (~2.4mb) model to upscale the latents used in a Stable Diffusion 1.5 or Stable Diffusion XL image generation, rather than the typical interpolation method, avoiding the traditional downsides of the latent upscale technique.
+
+**Node Link:** [https://github.com/gogurtenjoyer/latent-upscale](https://github.com/gogurtenjoyer/latent-upscale)
+
+---
+
+### Load Video Frame
+
+**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
+
+**Node Link:** https://github.com/helix4u/load_video_frame
+
+**Output Example:**
+
+
+
+
+
+
+---
+
+### Latent Upscale
+
+**Description:** This node uses a small (~2.4mb) model to upscale the latents used in a Stable Diffusion 1.5 or Stable Diffusion XL image generation, rather than the typical interpolation method, avoiding the traditional downsides of the latent upscale technique.
+
+**Node Link:** [https://github.com/gogurtenjoyer/latent-upscale](https://github.com/gogurtenjoyer/latent-upscale)
+
+---
+
+### Load Video Frame
+
+**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
+
+**Node Link:** https://github.com/helix4u/load_video_frame
+
+**Output Example:**
+
+ +
+---
+### Make 3D
+
+**Description:** Create compelling 3D stereo images from 2D originals.
+
+**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
+
+**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
+
+**Output Examples**
+
+
+
+
+---
+
+### Mask Operations
+
+Description: Offers logical operations (OR, SUB, AND) for combining and manipulating image masks.
+
+Node Link: https://github.com/VeyDlin/mask-operations-node
+
+View:
+
+
+
+---
+
+### Match Histogram
+
+**Description:** An InvokeAI node to match a histogram from one image to another. This is a bit like the `color correct` node in the main InvokeAI but this works in the YCbCr colourspace and can handle images of different sizes. Also does not require a mask input.
+- Option to only transfer luminance channel.
+- Option to save output as grayscale
+
+A good use case for this node is to normalize the colors of an image that has been through the tiled scaling workflow of my XYGrid Nodes.
+
+See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
+
+**Node Link:** https://github.com/skunkworxdark/match_histogram
+
+**Output Examples**
+
+
+
+---
+
+### Nightmare Promptgen
+
+**Description:** Nightmare Prompt Generator - Uses a local text generation model to create unique imaginative (but usually nightmarish) prompts for InvokeAI. By default, it allows you to choose from some gpt-neo models I finetuned on over 2500 of my own InvokeAI prompts in Compel format, but you're able to add your own, as well. Offers support for replacing any troublesome words with a random choice from list you can also define.
+
+**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
+
+---
+
+### Ollama Node
+
+**Description:** Uses Ollama API to expand text prompts for text-to-image generation using local LLMs. Works great for expanding basic prompts into detailed natural language prompts for Flux. Also provides a toggle to unload the LLM model immediately after expanding, to free up VRAM for Invoke to continue the image generation workflow.
+
+**Node Link:** https://github.com/Jonseed/Ollama-Node
+
+**Example Node Graph:** https://github.com/Jonseed/Ollama-Node/blob/main/Ollama-Node-Flux-example.json
+
+**View:**
+
+
+
+---
+
+### One Button Prompt
+
+
+
+---
+### Make 3D
+
+**Description:** Create compelling 3D stereo images from 2D originals.
+
+**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
+
+**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
+
+**Output Examples**
+
+
+
+
+---
+
+### Mask Operations
+
+Description: Offers logical operations (OR, SUB, AND) for combining and manipulating image masks.
+
+Node Link: https://github.com/VeyDlin/mask-operations-node
+
+View:
+
+
+
+---
+
+### Match Histogram
+
+**Description:** An InvokeAI node to match a histogram from one image to another. This is a bit like the `color correct` node in the main InvokeAI but this works in the YCbCr colourspace and can handle images of different sizes. Also does not require a mask input.
+- Option to only transfer luminance channel.
+- Option to save output as grayscale
+
+A good use case for this node is to normalize the colors of an image that has been through the tiled scaling workflow of my XYGrid Nodes.
+
+See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
+
+**Node Link:** https://github.com/skunkworxdark/match_histogram
+
+**Output Examples**
+
+
+
+---
+
+### Nightmare Promptgen
+
+**Description:** Nightmare Prompt Generator - Uses a local text generation model to create unique imaginative (but usually nightmarish) prompts for InvokeAI. By default, it allows you to choose from some gpt-neo models I finetuned on over 2500 of my own InvokeAI prompts in Compel format, but you're able to add your own, as well. Offers support for replacing any troublesome words with a random choice from list you can also define.
+
+**Node Link:** [https://github.com/gogurtenjoyer/nightmare-promptgen](https://github.com/gogurtenjoyer/nightmare-promptgen)
+
+---
+
+### Ollama Node
+
+**Description:** Uses Ollama API to expand text prompts for text-to-image generation using local LLMs. Works great for expanding basic prompts into detailed natural language prompts for Flux. Also provides a toggle to unload the LLM model immediately after expanding, to free up VRAM for Invoke to continue the image generation workflow.
+
+**Node Link:** https://github.com/Jonseed/Ollama-Node
+
+**Example Node Graph:** https://github.com/Jonseed/Ollama-Node/blob/main/Ollama-Node-Flux-example.json
+
+**View:**
+
+
+
+---
+
+### One Button Prompt
+
+ +
+**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
+
+The main node generates interesting prompts based on a set of parameters. There are also some additional nodes such as Auto Negative Prompt, One Button Artify, Create Prompt Variant and other cool prompt toys to play around with.
+
+**Node Link:** [https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI](https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI)
+
+**Nodes:**
+
+
+
+**Description:** an extensive suite of auto prompt generation and prompt helper nodes based on extensive logic. Get creative with the best prompt generator in the world.
+
+The main node generates interesting prompts based on a set of parameters. There are also some additional nodes such as Auto Negative Prompt, One Button Artify, Create Prompt Variant and other cool prompt toys to play around with.
+
+**Node Link:** [https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI](https://github.com/AIrjen/OneButtonPrompt_X_InvokeAI)
+
+**Nodes:**
+
+ +
+---
+
+### Oobabooga
+
+**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
+
+**Link:** https://github.com/sammyf/oobabooga-node
+
+**Example:**
+
+"describe a new mystical creature in its natural environment"
+
+*can return*
+
+"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
+As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
+
+
+
+---
+
+### Oobabooga
+
+**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
+
+**Link:** https://github.com/sammyf/oobabooga-node
+
+**Example:**
+
+"describe a new mystical creature in its natural environment"
+
+*can return*
+
+"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
+As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
+
+ +
+---
+
+### Remote Image
+
+**Description:** This is a pack of nodes to interoperate with other services, be they public websites or bespoke local servers. The pack consists of these nodes:
+
+- *Load Remote Image* - Lets you load remote images such as a realtime webcam image, an image of the day, or dynamically created images.
+- *Post Image to Remote Server* - Lets you upload an image to a remote server using an HTTP POST request, eg for storage, display or further processing.
+
+**Node Link:** https://github.com/fieldOfView/InvokeAI-remote_image
+
+---
+
+### BriaAI Remove Background
+
+**Description**: Implements one click background removal with BriaAI's new version 1.4 model which seems to be producing better results than any other previous background removal tool.
+
+**Node Link:** https://github.com/blessedcoolant/invoke_bria_rmbg
+
+**View**
+
+
+---
+
+### Remove Background
+
+Description: An integration of the rembg package to remove backgrounds from images using multiple U2NET models.
+
+Node Link: https://github.com/VeyDlin/remove-background-node
+
+View:
+
+
+
+---
+
+### Retroize
+
+**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
+
+**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
+
+**Retroize Output Examples**
+
+
+
+---
+
+### Remote Image
+
+**Description:** This is a pack of nodes to interoperate with other services, be they public websites or bespoke local servers. The pack consists of these nodes:
+
+- *Load Remote Image* - Lets you load remote images such as a realtime webcam image, an image of the day, or dynamically created images.
+- *Post Image to Remote Server* - Lets you upload an image to a remote server using an HTTP POST request, eg for storage, display or further processing.
+
+**Node Link:** https://github.com/fieldOfView/InvokeAI-remote_image
+
+---
+
+### BriaAI Remove Background
+
+**Description**: Implements one click background removal with BriaAI's new version 1.4 model which seems to be producing better results than any other previous background removal tool.
+
+**Node Link:** https://github.com/blessedcoolant/invoke_bria_rmbg
+
+**View**
+
+
+---
+
+### Remove Background
+
+Description: An integration of the rembg package to remove backgrounds from images using multiple U2NET models.
+
+Node Link: https://github.com/VeyDlin/remove-background-node
+
+View:
+
+
+
+---
+
+### Retroize
+
+**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
+
+**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
+
+**Retroize Output Examples**
+
+ +
+---
+
+### Simple Skin Detection
+
+Description: Detects skin in images based on predefined color thresholds.
+
+Node Link: https://github.com/VeyDlin/simple-skin-detection-node
+
+View:
+
+
+
+---
+
+### Size Stepper Nodes
+
+**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
+
+A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
+
+**Node Link:** https://github.com/dwringer/size-stepper-nodes
+
+**Example Usage:**
+
+
+
+---
+
+### Text font to Image
+
+**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
+
+**Node Link:** https://github.com/mickr777/textfontimage
+
+**Output Examples**
+
+
+
+---
+
+### Simple Skin Detection
+
+Description: Detects skin in images based on predefined color thresholds.
+
+Node Link: https://github.com/VeyDlin/simple-skin-detection-node
+
+View:
+
+
+
+---
+
+### Size Stepper Nodes
+
+**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
+
+A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
+
+**Node Link:** https://github.com/dwringer/size-stepper-nodes
+
+**Example Usage:**
+
+
+
+---
+
+### Text font to Image
+
+**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
+
+**Node Link:** https://github.com/mickr777/textfontimage
+
+**Output Examples**
+
+ +
+---
+
+### Example Node Template
+
+**Description:** This node allows you to do super cool things with InvokeAI.
+
+**Node Link:** https://github.com/invoke-ai/InvokeAI/blob/main/invokeai/app/invocations/prompt.py
+
+**Example Workflow:** https://github.com/invoke-ai/InvokeAI/blob/docs/main/docs/workflows/Prompt_from_File.json
+
+**Output Examples**
+
+
+
+
+## Disclaimer
+
+The nodes linked have been developed and contributed by members of the Invoke AI community. While we strive to ensure the quality and safety of these contributions, we do not guarantee the reliability or security of the nodes. If you have issues or concerns with any of the nodes below, please raise it on GitHub or in the Discord.
+
+
+## Help
+If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
diff --git a/docs/src/content/docs/features/Workflows/custom-node-manager.mdx b/docs/src/content/docs/features/Workflows/custom-node-manager.mdx
new file mode 100644
index 00000000000..ab42b73e5a6
--- /dev/null
+++ b/docs/src/content/docs/features/Workflows/custom-node-manager.mdx
@@ -0,0 +1,76 @@
+---
+title: Custom Node Manager
+sidebar:
+ order: 5
+---
+
+import { Steps } from '@astrojs/starlight/components';
+
+The Custom Node Manager installs, updates, and removes community node packs directly from the InvokeAI UI — no manual file copying, no restart required.
+
+## Opening the Custom Node Manager
+
+Click the **Nodes** tab (circuit icon) in the left sidebar, between **Models** and **Queue**.
+
+The page is split into two panels:
+
+- **Left:** the list of installed node packs, with each pack's node count, type badges, and on-disk path.
+- **Right:** the install UI, with tabs for **Git Repository URL** and **Scan Folder**, plus an install log at the bottom.
+
+## Installing a node pack
+
+
+
+---
+
+### Example Node Template
+
+**Description:** This node allows you to do super cool things with InvokeAI.
+
+**Node Link:** https://github.com/invoke-ai/InvokeAI/blob/main/invokeai/app/invocations/prompt.py
+
+**Example Workflow:** https://github.com/invoke-ai/InvokeAI/blob/docs/main/docs/workflows/Prompt_from_File.json
+
+**Output Examples**
+
+
+
+
+## Disclaimer
+
+The nodes linked have been developed and contributed by members of the Invoke AI community. While we strive to ensure the quality and safety of these contributions, we do not guarantee the reliability or security of the nodes. If you have issues or concerns with any of the nodes below, please raise it on GitHub or in the Discord.
+
+
+## Help
+If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
diff --git a/docs/src/content/docs/features/Workflows/custom-node-manager.mdx b/docs/src/content/docs/features/Workflows/custom-node-manager.mdx
new file mode 100644
index 00000000000..ab42b73e5a6
--- /dev/null
+++ b/docs/src/content/docs/features/Workflows/custom-node-manager.mdx
@@ -0,0 +1,76 @@
+---
+title: Custom Node Manager
+sidebar:
+ order: 5
+---
+
+import { Steps } from '@astrojs/starlight/components';
+
+The Custom Node Manager installs, updates, and removes community node packs directly from the InvokeAI UI — no manual file copying, no restart required.
+
+## Opening the Custom Node Manager
+
+Click the **Nodes** tab (circuit icon) in the left sidebar, between **Models** and **Queue**.
+
+The page is split into two panels:
+
+- **Left:** the list of installed node packs, with each pack's node count, type badges, and on-disk path.
+- **Right:** the install UI, with tabs for **Git Repository URL** and **Scan Folder**, plus an install log at the bottom.
+
+## Installing a node pack
+
++ **Invalid Hotkeys:** `mod+` (no key after modifier), `shift+ctrl+` (ends with modifier) +::: + +--- + +## Developer Guide + +The hotkeys system allows developers to centrally define, manage, and validate hotkeys throughout the application. It is built on top of `react-hotkeys-hook`. + +### Architecture + +The customizable hotkeys feature comprises the following components: + +
...
;
+ };
+ ```
+ for Creatives + tagline: Invoke is a free and open-source creative engine for AI-powered image generation. Built by creatives, for creatives. Self-hosted, fully customizable, and Apache 2.0 licensed. + actions: + - text: Get Started + link: start-here/installation + icon: right-arrow + variant: primary + - text: View on GitHub + link: https://github.com/invoke-ai/InvokeAI + icon: github + variant: minimal +--- + +import { Image } from 'astro:assets' +import { Card, CardGrid, LinkButton } from '@astrojs/starlight/components'; +import DownloadOptions from '@components/DownloadOptions.astro'; + +import splashImage from './assets/invoke-webui-canvas.png'; + +
+
+
+## The Creative Engine
+
+Invoke provides the most feature-complete and professional toolkit for AI image generation, built with production workflows in mind.
+
+Detailed Discussion
+ +Python (and PyTorch) relies on the memory allocator from the C Standard Library (`libc`). On linux, with the GNU C Standard Library implementation (`glibc`), our memory access patterns have been observed to cause severe memory fragmentation. + +This fragmentation results in large amounts of memory that has been freed but can't be released back to the OS. Loading models from disk and moving them between CPU/CUDA seem to be the operations that contribute most to the fragmentation. + +This memory fragmentation issue can result in OOM crashes during frequent model switching, even if `ram` (the max RAM cache size) is set to a reasonable value (e.g. a OOM crash with `ram=16` on a system with 32GB of RAM). + +This problem may also exist on other OSes, and other `libc` implementations. But, at the time of writing, it has only been investigated on linux with `glibc`. + +To better understand how the `glibc` memory allocator works, see these references: + +- Basics: [The GNU Allocator](https://www.gnu.org/software/libc/manual/html_node/The-GNU-Allocator.html) +- Details: [Malloc Internals](https://sourceware.org/glibc/wiki/MallocInternals) + +Note the differences between memory allocated as chunks in an arena vs. memory allocated with `mmap`. Under `glibc`'s default configuration, most model tensors get allocated as chunks in an arena making them vulnerable to the problem of fragmentation. + +[model install docs]: ../../concepts/models +[system requirements]: ../../start-here/system-requirements +[Low VRAM mode guide]: ../../configuration/low-vram-mode +[create an issue]: https://github.com/invoke-ai/InvokeAI/issues +[discord]: https://discord.gg/ZmtBAhwWhy +[configuration docs]: ../../configuration/invokeai-yaml diff --git a/docs/src/content/i18n/en.json b/docs/src/content/i18n/en.json new file mode 100644 index 00000000000..69333e3a0b2 --- /dev/null +++ b/docs/src/content/i18n/en.json @@ -0,0 +1,45 @@ +{ + "skipLink.label": "Skip to content", + "search.label": "Search", + "search.ctrlKey": "Ctrl", + "search.cancelLabel": "Cancel", + "search.devWarning": "Search is only available in production builds. \nTry building and previewing the site to test it out locally.", + "themeSelect.accessibleLabel": "Select theme", + "themeSelect.dark": "Dark", + "themeSelect.light": "Light", + "themeSelect.auto": "Auto", + "languageSelect.accessibleLabel": "Select language", + "menuButton.accessibleLabel": "Menu", + "sidebarNav.accessibleLabel": "Main", + "tableOfContents.onThisPage": "On this page", + "tableOfContents.overview": "Overview", + "i18n.untranslatedContent": "This content is not available in your language yet.", + "page.editLink": "Edit page", + "page.lastUpdated": "Last updated:", + "page.previousLink": "Previous", + "page.nextLink": "Next", + "page.draft": "This content is a draft and will not be included in production builds.", + "404.text": "Page not found. Check the URL or try using the search bar.", + "aside.note": "Note", + "aside.tip": "Tip", + "aside.caution": "Caution", + "aside.danger": "Danger", + "fileTree.directory": "Directory", + "builtWithStarlight.label": "Built with Starlight", + "heading.anchorLabel": "Section titled “{{title}}”", + + "expressiveCode.copyButtonCopied": "Copied!", + "expressiveCode.copyButtonTooltip": "Copy to clipboard", + "expressiveCode.terminalWindowFallbackTitle": "Terminal window", + + "pagefind.clear_search": "Clear", + "pagefind.load_more": "Load more results", + "pagefind.search_label": "Search this site", + "pagefind.filters_label": "Filters", + "pagefind.zero_results": "No results for [SEARCH_TERM]", + "pagefind.many_results": "[COUNT] results for [SEARCH_TERM]", + "pagefind.one_result": "[COUNT] result for [SEARCH_TERM]", + "pagefind.alt_search": "No results for [SEARCH_TERM]. Showing results for [DIFFERENT_TERM] instead", + "pagefind.search_suggestion": "No results for [SEARCH_TERM]. Try one of the following searches:", + "pagefind.searching": "Searching for [SEARCH_TERM]..." +} diff --git a/docs/src/generated/invocation-context.json b/docs/src/generated/invocation-context.json new file mode 100644 index 00000000000..55116ec69dd --- /dev/null +++ b/docs/src/generated/invocation-context.json @@ -0,0 +1,657 @@ +{ + "description": "Provides access to various services and data for the current invocation.\n\nAttributes:\n images (ImagesInterface): Methods to save, get and update images and their metadata.\n tensors (TensorsInterface): Methods to save and get tensors, including image, noise, masks, and masked images.\n conditioning (ConditioningInterface): Methods to save and get conditioning data.\n models (ModelsInterface): Methods to check if a model exists, get a model, and get a model's info.\n logger (LoggerInterface): The app logger.\n config (ConfigInterface): The app config.\n util (UtilInterface): Utility methods, including a method to check if an invocation was canceled and step callbacks.\n boards (BoardsInterface): Methods to interact with boards.", + "interfaces": [ + { + "description": "", + "methods": [ + { + "description": "Gets an image as an ImageDTO object.", + "name": "get_dto", + "parameters": [ + { + "default": "", + "description": "The name of the image to get.", + "name": "image_name", + "type": "str" + } + ], + "return_type": "ImageDTO", + "returns": "The image as an ImageDTO object.", + "signature": "(image_name: str) -> ImageDTO" + }, + { + "description": "Gets an image's metadata, if it has any.", + "name": "get_metadata", + "parameters": [ + { + "default": "", + "description": "The name of the image to get the metadata for.", + "name": "image_name", + "type": "str" + } + ], + "return_type": "Optional[MetadataField]", + "returns": "The image's metadata, if it has any.", + "signature": "(image_name: str) -> Optional[MetadataField]" + }, + { + "description": "Gets the internal path to an image or thumbnail.", + "name": "get_path", + "parameters": [ + { + "default": "", + "description": "The name of the image to get the path of.", + "name": "image_name", + "type": "str" + }, + { + "default": "False", + "description": "Get the path of the thumbnail instead of the full image", + "name": "thumbnail", + "type": "bool" + } + ], + "return_type": "Path", + "returns": "The local path of the image or thumbnail.", + "signature": "(image_name: str, thumbnail: bool = False) -> Path" + }, + { + "description": "Gets an image as a PIL Image object. This method returns a copy of the image.", + "name": "get_pil", + "parameters": [ + { + "default": "", + "description": "The name of the image to get.", + "name": "image_name", + "type": "str" + }, + { + "default": "None", + "description": "The color mode to convert the image to. If None, the original mode is used.", + "name": "mode", + "type": "Optional[Literal['L', 'RGB', 'RGBA', 'CMYK', 'YCbCr', 'LAB', 'HSV', 'I', 'F']]" + } + ], + "return_type": "Image", + "returns": "The image as a PIL Image object.", + "signature": "(image_name: str, mode: Optional[Literal['L', 'RGB', 'RGBA', 'CMYK', 'YCbCr', 'LAB', 'HSV', 'I', 'F']] = None) -> Image" + }, + { + "description": "Saves an image, returning its DTO.\nIf the current queue item has a workflow or metadata, it is automatically saved with the image.", + "name": "save", + "parameters": [ + { + "default": "", + "description": "The image to save, as a PIL image.", + "name": "image", + "type": "Image" + }, + { + "default": "None", + "description": "The board ID to add the image to, if it should be added. It the invocation inherits from `WithBoard`, that board will be used automatically. **Use this only if you want to override or provide a board manually!**", + "name": "board_id", + "type": "Optional[str]" + }, + { + "default": "ImageCategory.GENERAL", + "description": "The category of the image. Only the GENERAL category is added to the gallery.", + "name": "image_category", + "type": "ImageCategory" + }, + { + "default": "None", + "description": "The metadata to save with the image, if it should have any. If the invocation inherits from `WithMetadata`, that metadata will be used automatically. **Use this only if you want to override or provide metadata manually!**", + "name": "metadata", + "type": "Optional[MetadataField]" + } + ], + "return_type": "ImageDTO", + "returns": "The saved image DTO.", + "signature": "(image: Image, board_id: Optional[str] = None, image_category: ImageCategory = ImageCategory.GENERAL, metadata: Optional[MetadataField] = None) -> ImageDTO" + } + ], + "name": "ImagesInterface" + }, + { + "description": "", + "methods": [ + { + "description": "Loads a tensor by name. This method returns a copy of the tensor.", + "name": "load", + "parameters": [ + { + "default": "", + "description": "The name of the tensor to load.", + "name": "name", + "type": "str" + } + ], + "return_type": "Tensor", + "returns": "The tensor.", + "signature": "(name: str) -> Tensor" + }, + { + "description": "Saves a tensor, returning its name.", + "name": "save", + "parameters": [ + { + "default": "", + "description": "The tensor to save.", + "name": "tensor", + "type": "Tensor" + } + ], + "return_type": "str", + "returns": "The name of the saved tensor.", + "signature": "(tensor: Tensor) -> str" + } + ], + "name": "TensorsInterface" + }, + { + "description": "", + "methods": [ + { + "description": "Loads conditioning data by name. This method returns a copy of the conditioning data.", + "name": "load", + "parameters": [ + { + "default": "", + "description": "The name of the conditioning data to load.", + "name": "name", + "type": "str" + } + ], + "return_type": "ConditioningFieldData", + "returns": "The conditioning data.", + "signature": "(name: str) -> ConditioningFieldData" + }, + { + "description": "Saves a conditioning data object, returning its name.", + "name": "save", + "parameters": [ + { + "default": "", + "description": "The conditioning data to save.", + "name": "conditioning_data", + "type": "ConditioningFieldData" + } + ], + "return_type": "str", + "returns": "The name of the saved conditioning data.", + "signature": "(conditioning_data: ConditioningFieldData) -> str" + } + ], + "name": "ConditioningInterface" + }, + { + "description": "Common API for loading, downloading and managing models.", + "methods": [ + { + "description": "Download the model file located at source to the models cache and return its Path.\nThis can be used to single-file install models and other resources of arbitrary types\nwhich should not get registered with the database. If the model is already\ninstalled, the cached path will be returned. Otherwise it will be downloaded.", + "name": "download_and_cache_model", + "parameters": [ + { + "default": "", + "description": "A URL that points to the model, or a huggingface repo_id.", + "name": "source", + "type": "str | AnyHttpUrl" + } + ], + "return_type": "Path", + "returns": "Path to the downloaded model", + "signature": "(source: str | AnyHttpUrl) -> Path" + }, + { + "description": "Check if a model exists.", + "name": "exists", + "parameters": [ + { + "default": "", + "description": "The key or ModelField representing the model.", + "name": "identifier", + "type": "Union[str, ModelIdentifierField]" + } + ], + "return_type": "bool", + "returns": "True if the model exists, False if not.", + "signature": "(identifier: Union[str, ModelIdentifierField]) -> bool" + }, + { + "description": "Gets the absolute path for a given model config or path.\nFor example, if the model's path is `flux/main/FLUX Dev.safetensors`, and the models path is\n`/home/username/InvokeAI/models`, this method will return\n`/home/username/InvokeAI/models/flux/main/FLUX Dev.safetensors`.", + "name": "get_absolute_path", + "parameters": [ + { + "default": "", + "description": "The model config or path.", + "name": "config_or_path", + "type": "Union[AnyModelConfig, Path, str]" + } + ], + "return_type": "Path", + "returns": "The absolute path to the model.", + "signature": "(config_or_path: Union[AnyModelConfig, Path, str]) -> Path" + }, + { + "description": "Get a model's config.", + "name": "get_config", + "parameters": [ + { + "default": "", + "description": "The key or ModelField representing the model.", + "name": "identifier", + "type": "Union[str, ModelIdentifierField]" + } + ], + "return_type": "AnyModelConfig", + "returns": "The model's config.", + "signature": "(identifier: Union[str, ModelIdentifierField]) -> AnyModelConfig" + }, + { + "description": "Load a model.", + "name": "load", + "parameters": [ + { + "default": "", + "description": "The key or ModelField representing the model.", + "name": "identifier", + "type": "Union[str, ModelIdentifierField]" + }, + { + "default": "None", + "description": "The submodel of the model to get.", + "name": "submodel_type", + "type": "Optional[SubModelType]" + } + ], + "return_type": "LoadedModel", + "returns": "An object representing the loaded model.", + "signature": "(identifier: Union[str, ModelIdentifierField], submodel_type: Optional[SubModelType] = None) -> LoadedModel" + }, + { + "description": "Load a model by its attributes.", + "name": "load_by_attrs", + "parameters": [ + { + "default": "", + "description": "Name of the model.", + "name": "name", + "type": "str" + }, + { + "default": "", + "description": "The models' base type, e.g. `BaseModelType.StableDiffusion1`, `BaseModelType.StableDiffusionXL`, etc.", + "name": "base", + "type": "BaseModelType" + }, + { + "default": "", + "description": "Type of the model, e.g. `ModelType.Main`, `ModelType.Vae`, etc.", + "name": "type", + "type": "ModelType" + }, + { + "default": "None", + "description": "The type of submodel to load, e.g. `SubModelType.UNet`, `SubModelType.TextEncoder`, etc. Only main models have submodels.", + "name": "submodel_type", + "type": "Optional[SubModelType]" + } + ], + "return_type": "LoadedModel", + "returns": "An object representing the loaded model.", + "signature": "(name: str, base: BaseModelType, type: ModelType, submodel_type: Optional[SubModelType] = None) -> LoadedModel" + }, + { + "description": "Load the model file located at the indicated path\nIf a loader callable is provided, it will be invoked to load the model. Otherwise,\n`safetensors.torch.load_file()` or `torch.load()` will be called to load the model.\nBe aware that the LoadedModelWithoutConfig object has no `config` attribute", + "name": "load_local_model", + "parameters": [ + { + "default": "", + "description": "", + "name": "model_path", + "type": "Path" + }, + { + "default": "None", + "description": "A Callable that expects a Path and returns a dict[str|int, Any]", + "name": "loader", + "type": "Optional[Callable[[Path], AnyModel]]" + } + ], + "return_type": "LoadedModelWithoutConfig", + "returns": "A LoadedModelWithoutConfig object.", + "signature": "(model_path: Path, loader: Optional[Callable[[Path], AnyModel]] = None) -> LoadedModelWithoutConfig" + }, + { + "description": "Download, cache, and load the model file located at the indicated URL or repo_id.\nIf the model is already downloaded, it will be loaded from the cache.\nIf the a loader callable is provided, it will be invoked to load the model. Otherwise,\n`safetensors.torch.load_file()` or `torch.load()` will be called to load the model.\nBe aware that the LoadedModelWithoutConfig object has no `config` attribute", + "name": "load_remote_model", + "parameters": [ + { + "default": "", + "description": "A URL or huggingface repoid.", + "name": "source", + "type": "str | AnyHttpUrl" + }, + { + "default": "None", + "description": "A Callable that expects a Path and returns a dict[str|int, Any]", + "name": "loader", + "type": "Optional[Callable[[Path], AnyModel]]" + } + ], + "return_type": "LoadedModelWithoutConfig", + "returns": "A LoadedModelWithoutConfig object.", + "signature": "(source: str | AnyHttpUrl, loader: Optional[Callable[[Path], AnyModel]] = None) -> LoadedModelWithoutConfig" + }, + { + "description": "Search for models by attributes.", + "name": "search_by_attrs", + "parameters": [ + { + "default": "None", + "description": "The name to search for (exact match).", + "name": "name", + "type": "Optional[str]" + }, + { + "default": "None", + "description": "The base to search for, e.g. `BaseModelType.StableDiffusion1`, `BaseModelType.StableDiffusionXL`, etc.", + "name": "base", + "type": "Optional[BaseModelType]" + }, + { + "default": "None", + "description": "Type type of model to search for, e.g. `ModelType.Main`, `ModelType.Vae`, etc.", + "name": "type", + "type": "Optional[ModelType]" + }, + { + "default": "None", + "description": "The format of model to search for, e.g. `ModelFormat.Checkpoint`, `ModelFormat.Diffusers`, etc.", + "name": "format", + "type": "Optional[ModelFormat]" + } + ], + "return_type": "list[AnyModelConfig]", + "returns": "A list of models that match the attributes.", + "signature": "(name: Optional[str] = None, base: Optional[BaseModelType] = None, type: Optional[ModelType] = None, format: Optional[ModelFormat] = None) -> list[AnyModelConfig]" + }, + { + "description": "Search for models by path.", + "name": "search_by_path", + "parameters": [ + { + "default": "", + "description": "The path to search for.", + "name": "path", + "type": "Path" + } + ], + "return_type": "list[AnyModelConfig]", + "returns": "A list of models that match the path.", + "signature": "(path: Path) -> list[AnyModelConfig]" + } + ], + "name": "ModelsInterface" + }, + { + "description": "", + "methods": [ + { + "description": "Logs a debug message.", + "name": "debug", + "parameters": [ + { + "default": "", + "description": "The message to log.", + "name": "message", + "type": "str" + } + ], + "return_type": "None", + "returns": "", + "signature": "(message: str) -> None" + }, + { + "description": "Logs an error message.", + "name": "error", + "parameters": [ + { + "default": "", + "description": "The message to log.", + "name": "message", + "type": "str" + } + ], + "return_type": "None", + "returns": "", + "signature": "(message: str) -> None" + }, + { + "description": "Logs an info message.", + "name": "info", + "parameters": [ + { + "default": "", + "description": "The message to log.", + "name": "message", + "type": "str" + } + ], + "return_type": "None", + "returns": "", + "signature": "(message: str) -> None" + }, + { + "description": "Logs a warning message.", + "name": "warning", + "parameters": [ + { + "default": "", + "description": "The message to log.", + "name": "message", + "type": "str" + } + ], + "return_type": "None", + "returns": "", + "signature": "(message: str) -> None" + } + ], + "name": "LoggerInterface" + }, + { + "description": "", + "methods": [ + { + "description": "Gets the app's config.", + "name": "get", + "parameters": [], + "return_type": "InvokeAIAppConfig", + "returns": "The app's config.", + "signature": "() -> InvokeAIAppConfig" + } + ], + "name": "ConfigInterface" + }, + { + "description": "", + "methods": [ + { + "description": "The step callback for FLUX.2 Klein models (32-channel VAE).", + "name": "flux2_step_callback", + "parameters": [ + { + "default": "", + "description": "The intermediate state of the diffusion pipeline.", + "name": "intermediate_state", + "type": "PipelineIntermediateState" + } + ], + "return_type": "None", + "returns": "", + "signature": "(intermediate_state: PipelineIntermediateState) -> None" + }, + { + "description": "The step callback emits a progress event with the current step, the total number of\nsteps, a preview image, and some other internal metadata.\nThis should be called after each denoising step.", + "name": "flux_step_callback", + "parameters": [ + { + "default": "", + "description": "The intermediate state of the diffusion pipeline.", + "name": "intermediate_state", + "type": "PipelineIntermediateState" + } + ], + "return_type": "None", + "returns": "", + "signature": "(intermediate_state: PipelineIntermediateState) -> None" + }, + { + "description": "Checks if the current session has been canceled.", + "name": "is_canceled", + "parameters": [], + "return_type": "bool", + "returns": "True if the current session has been canceled, False if not.", + "signature": "() -> bool" + }, + { + "description": "The step callback emits a progress event with the current step, the total number of\nsteps, a preview image, and some other internal metadata.\nThis should be called after each denoising step.", + "name": "sd_step_callback", + "parameters": [ + { + "default": "", + "description": "The intermediate state of the diffusion pipeline.", + "name": "intermediate_state", + "type": "PipelineIntermediateState" + }, + { + "default": "", + "description": "The base model for the current denoising step.", + "name": "base_model", + "type": "BaseModelType" + } + ], + "return_type": "None", + "returns": "", + "signature": "(intermediate_state: PipelineIntermediateState, base_model: BaseModelType) -> None" + }, + { + "description": "Signals the progress of some long-running invocation. The progress is displayed in the UI.\nIf a percentage is provided, the UI will display a progress bar and automatically append the percentage to the\nmessage. You should not include the percentage in the message.\nExample:\n```py\ntotal_steps = 10\nfor i in range(total_steps):\npercentage = i / (total_steps - 1)\ncontext.util.signal_progress(\"Doing something cool\", percentage)\n```\nIf an image is provided, the UI will display it. If your image should be displayed at a different size, provide\na tuple of `(width, height)` for the `image_size` parameter. The image will be displayed at the specified size\nin the UI.\nFor example, SD denoising progress images are 1/8 the size of the original image, so you'd do this to ensure the\nimage is displayed at the correct size:\n```py\n# Calculate the output size of the image (8x the progress image's size)\nwidth = progress_image.width * 8\nheight = progress_image.height * 8\n# Signal the progress with the image and output size\nsignal_progress(\"Denoising\", percentage, progress_image, (width, height))\n```\nIf your progress image is very large, consider downscaling it to reduce the payload size and provide the original\nsize to the `image_size` parameter. The PIL `thumbnail` method is useful for this, as it maintains the aspect\nratio of the image:\n```py\n# `thumbnail` modifies the image in-place, so we need to first make a copy\nthumbnail_image = progress_image.copy()\n# Resize the image to a maximum of 256x256 pixels, maintaining the aspect ratio\nthumbnail_image.thumbnail((256, 256))\n# Signal the progress with the thumbnail, passing the original size\nsignal_progress(\"Denoising\", percentage, thumbnail, progress_image.size)\n```", + "name": "signal_progress", + "parameters": [ + { + "default": "", + "description": "A message describing the current status. Do not include the percentage in this message.", + "name": "message", + "type": "str" + }, + { + "default": "None", + "description": "The current percentage completion for the process. Omit for indeterminate progress.", + "name": "percentage", + "type": "float | None" + }, + { + "default": "None", + "description": "An optional image to display.", + "name": "image", + "type": "Image | None" + }, + { + "default": "None", + "description": "The optional size of the image to display. If omitted, the image will be displayed at its original size.", + "name": "image_size", + "type": "tuple[int, int] | None" + } + ], + "return_type": "None", + "returns": "", + "signature": "(message: str, percentage: float | None = None, image: Image | None = None, image_size: tuple[int, int] | None = None) -> None" + } + ], + "name": "UtilInterface" + }, + { + "description": "", + "methods": [ + { + "description": "Adds an image to a board.", + "name": "add_image_to_board", + "parameters": [ + { + "default": "", + "description": "The ID of the board to add the image to.", + "name": "board_id", + "type": "str" + }, + { + "default": "", + "description": "The name of the image to add to the board.", + "name": "image_name", + "type": "str" + } + ], + "return_type": "None", + "returns": "", + "signature": "(board_id: str, image_name: str) -> None" + }, + { + "description": "Creates a board for the current user.", + "name": "create", + "parameters": [ + { + "default": "", + "description": "The name of the board to create.", + "name": "board_name", + "type": "str" + } + ], + "return_type": "BoardDTO", + "returns": "The created board DTO.", + "signature": "(board_name: str) -> BoardDTO" + }, + { + "description": "Gets all boards accessible to the current user.", + "name": "get_all", + "parameters": [], + "return_type": "list[BoardDTO]", + "returns": "A list of all boards accessible to the current user.", + "signature": "() -> list[BoardDTO]" + }, + { + "description": "Gets all image names for a board.", + "name": "get_all_image_names_for_board", + "parameters": [ + { + "default": "", + "description": "The ID of the board to get the image names for.", + "name": "board_id", + "type": "str" + } + ], + "return_type": "list[str]", + "returns": "A list of all image names for the board.", + "signature": "(board_id: str) -> list[str]" + }, + { + "description": "Gets a board DTO.", + "name": "get_dto", + "parameters": [ + { + "default": "", + "description": "The ID of the board to get.", + "name": "board_id", + "type": "str" + } + ], + "return_type": "BoardDTO", + "returns": "The board DTO.", + "signature": "(board_id: str) -> BoardDTO" + } + ], + "name": "BoardsInterface" + } + ], + "name": "InvocationContext" +} diff --git a/docs/src/generated/settings.json b/docs/src/generated/settings.json new file mode 100644 index 00000000000..1987a90abce --- /dev/null +++ b/docs/src/generated/settings.json @@ -0,0 +1,843 @@ +{ + "settings": [ + { + "category": "WEB", + "default": "127.0.0.1", + "description": "IP address to bind to. Use `0.0.0.0` to serve to your local network.", + "env_var": "INVOKEAI_HOST", + "literal_values": [], + "name": "host", + "required": false, + "type": "Valid values: `auto`, `cpu`, `cuda`, `mps`, `cuda:N` (where N is a device number)", + "env_var": "INVOKEAI_DEVICE", + "literal_values": [], + "name": "device", + "required": false, + "type": "
Valid values: `auto`, or a list whose entries are each `cpu`, `cuda`, `mps`, or `cuda:N` (where N is a device number)", + "env_var": "INVOKEAI_GENERATION_DEVICES", + "literal_values": [], + "name": "generation_devices", + "required": false, + "type": "typing.Union[typing.Literal['auto'], list[str]]", + "validation": {} + }, + { + "category": "DEVICE", + "default": "auto", + "description": "Floating point precision. `float16` will consume half the memory of `float32` but produce slightly lower-quality images. The `auto` setting will guess the proper precision based on your video card and operating system.", + "env_var": "INVOKEAI_PRECISION", + "literal_values": [ + "auto", + "float16", + "bfloat16", + "float32" + ], + "name": "precision", + "required": false, + "type": "typing.Literal['auto', 'float16', 'bfloat16', 'float32']", + "validation": {} + }, + { + "category": "GENERATION", + "default": false, + "description": "Whether to calculate guidance in serial instead of in parallel, lowering memory requirements.", + "env_var": "INVOKEAI_SEQUENTIAL_GUIDANCE", + "literal_values": [], + "name": "sequential_guidance", + "required": false, + "type": "
+ This site was designed and developed by Aether Fox Studio.
+
+
+
diff --git a/docs/src/lib/components/ForceDarkTheme.astro b/docs/src/lib/components/ForceDarkTheme.astro
new file mode 100644
index 00000000000..f9c102a1ce8
--- /dev/null
+++ b/docs/src/lib/components/ForceDarkTheme.astro
@@ -0,0 +1,12 @@
+---
+
+---
+
+
+
diff --git a/docs/src/lib/components/InvocationContextDocs.astro b/docs/src/lib/components/InvocationContextDocs.astro
new file mode 100644
index 00000000000..851ac8a25b1
--- /dev/null
+++ b/docs/src/lib/components/InvocationContextDocs.astro
@@ -0,0 +1,324 @@
+---
+import invocationContext from '../../generated/invocation-context.json';
+
+/** Strip "Interface" suffix for the access path hint, e.g. "ImagesInterface" -> "context.images" */
+const accessPath = (name: string) => {
+ const stripped = name.replace(/Interface$/, '').toLowerCase();
+ return `context.${stripped}`;
+};
+
+/** Build a URL-friendly anchor id from an interface name, e.g. "ImagesInterface" -> "imagesinterface" */
+const ifaceId = (name: string) => name.toLowerCase();
+
+/** Build a URL-friendly anchor id for a method, e.g. ("ImagesInterface","get_dto") -> "imagesinterface--get_dto" */
+const methodId = (ifaceName: string, methodName: string) =>
+ `${ifaceName.toLowerCase()}--${methodName}`;
+
+/** Lightweight markdown-to-HTML for docstring content.
+ * Handles: fenced code blocks (```lang ... ```), inline `code`, **bold**, and paragraphs. */
+const miniMarkdown = (text: string): string => {
+ // HTML-escape first
+ let s = text.replace(/&/g, '&').replace(//g, '>');
+ // Fenced code blocks: ```lang\n...\n```
+ s = s.replace(/```(\w*)\n([\s\S]*?)```/g, (_m, lang, code) => {
+ return `${code.replace(/^\n|\n$/g, '')}$1');
+ // Bold: **...**
+ s = s.replace(/\*\*([^*]+)\*\*/g, '$1');
+ // Convert double newlines to paragraph breaks
+ s = s.replace(/\n\n+/g, ''); + return `
${s}
`; +}; + +/** Inline-only markdown: just backtick `code` and **bold**, no block elements. */ +const inlineMarkdown = (text: string): string => { + let s = text.replace(/&/g, '&').replace(//g, '>'); + s = s.replace(/`([^`]+)`/g, '$1');
+ s = s.replace(/\*\*([^*]+)\*\*/g, '$1');
+ return s;
+};
+
+/** Get the first sentence/line of a description for the summary table. */
+const summaryDesc = (desc: string) => {
+ if (!desc) return '';
+ // Take up to first newline or period+space
+ const nl = desc.indexOf('\n');
+ const trimmed = nl !== -1 ? desc.substring(0, nl) : desc;
+ return trimmed;
+};
+---
+
+{invocationContext.interfaces.map((iface) => (
+
+
+ {iface.name}
+
+
+ {iface.description && }
+
+ {/* ── Summary table ── */}
+
+
+
+
+ {/* ── Per-method details ── */}
+ {iface.methods.map((method) => (
+
+))}
+
+
diff --git a/docs/src/lib/components/Link.astro b/docs/src/lib/components/Link.astro
new file mode 100644
index 00000000000..cca88478340
--- /dev/null
+++ b/docs/src/lib/components/Link.astro
@@ -0,0 +1,23 @@
+---
+type Props = {
+ href: string;
+ label?: string;
+ [key: string]: any;
+};
+
+const { href, label, ...rest } = Astro.props as Props;
+
+const useSlot = !!Astro.slots.has('default');
+const isExternal = /^https?:\/\//.test(href);
+---
+
+
+ {useSlot ?
+ {iface.name}
+ {accessPath(iface.name)}
+
+
+ {iface.description && }
+
+ {/* ── Summary table ── */}
+ | Method | +Description | +
|---|---|
{method.name} |
+ + |
+
+
+
+
+ )}
+
+ {(method.returns || method.return_type) && (
+ <>
+
+
+
+
+ )}
+
+ ))}
+ {method.name}
+ +{method.signature}Parameters
+| Name | +Type | +Description | +Default | +
|---|---|---|---|
{param.name} |
+ {param.type || '—'} |
+ + | {param.default ? {param.default} : required} |
+
Returns
+| Type | +Description | +
|---|---|
{method.return_type || '—'} |
+ + |
Loading diagram...
+
+
+
+Source
+
+
+))}
+
+
diff --git a/docs/src/lib/components/SplashGallery.astro b/docs/src/lib/components/SplashGallery.astro
new file mode 100644
index 00000000000..a0293e48ff6
--- /dev/null
+++ b/docs/src/lib/components/SplashGallery.astro
@@ -0,0 +1,263 @@
+---
+// Community Gallery Marquee
+
+import {Image} from 'astro:assets';
+
+import linearview from '../../content/docs/workflows/assets/linearview.png';
+import workflowLibrary from '../../content/docs/workflows/assets/workflow_library.png';
+import groupsMultigenSeeding from '../../content/docs/workflows/assets/groupsmultigenseeding.png';
+import groupsImgVae from '../../content/docs/workflows/assets/groupsimgvae.png';
+import groupsConditioning from '../../content/docs/workflows/assets/groupsconditioning.png';
+import groupsControl from '../../content/docs/workflows/assets/groupscontrol.png';
+import groupsLora from '../../content/docs/workflows/assets/groupslora.png';
+import groupsNoise from '../../content/docs/workflows/assets/groupsnoise.png';
+import groupsIterate from '../../content/docs/workflows/assets/groupsiterate.png';
+
+const placeholderSocials = [
+ { label: 'Instagram', href: 'https://example.com/instagram' },
+ { label: 'X', href: 'https://example.com/x' },
+ { label: 'ArtStation', href: 'https://example.com/artstation' },
+];
+
+const rows = [
+ [
+ {
+ id: 'linearview',
+ image: linearview,
+ alt: 'Linear workflow editor view',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'workflow-library',
+ image: workflowLibrary,
+ alt: 'Workflow library browser view',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'conditioning',
+ image: groupsConditioning,
+ alt: 'Workflow conditioning group',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'img-vae',
+ image: groupsImgVae,
+ alt: 'Workflow image and VAE group',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'multigen',
+ image: groupsMultigenSeeding,
+ alt: 'Workflow multigen seeding group',
+ socials: placeholderSocials,
+ },
+ ],
+ [
+ {
+ id: 'control',
+ image: groupsControl,
+ alt: 'Workflow control group',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'lora',
+ image: groupsLora,
+ alt: 'Workflow LoRA group',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'noise',
+ image: groupsNoise,
+ alt: 'Workflow noise group',
+ socials: placeholderSocials,
+ },
+ {
+ id: 'iterate',
+ image: groupsIterate,
+ alt: 'Workflow iterate group',
+ socials: placeholderSocials,
+ },
+ ],
+];
+---
+
++ {formatCategoryName(category)} + {settings.length} +
+-
+ {settings.map((setting) => (
+
-
+
{setting.name}+
+
+ -
+ Type
+
{formatType(setting.type)}+
+ -
+ Default
+
{formatValue(setting.default)}+
+ -
+ Env
+
{setting.env_var}+
+
+ -
+ {setting.description}
+ {setting.literal_values.length > 0 && (
+
+ Values: {setting.literal_values.map((v) =>
{formatValue(v)}).reduce((prev, curr) => [prev, ' ', curr])} + + )} + {Object.keys(setting.validation).length > 0 && ( + + {Object.entries(setting.validation).map(([key, value]) => ( +{key}={formatValue(value)}+ )).reduce((prev, curr) => [prev, ' ', curr])} + + )} +
+
+
+
+ ))}
+
+ {rows.map((row, rowIndex) => (
+
+
+
diff --git a/docs/src/lib/components/SystemRequirmentsLink.astro b/docs/src/lib/components/SystemRequirmentsLink.astro
new file mode 100644
index 00000000000..16455b8e749
--- /dev/null
+++ b/docs/src/lib/components/SystemRequirmentsLink.astro
@@ -0,0 +1,10 @@
+---
+import { LinkCard } from '@astrojs/starlight/components';
+import { withBase } from '../base-path';
+---
+
+
+
+ ))}
+
+
+ {[...Array(2)].map((_, segmentIndex) => (
+
+
+ {row.map((tile) => (
+
+
+ Submitted by
+
+
+
+ ))}
+
+ ))}
+ Valid values: `flat`, `date`, `type`, `hash` custom_nodes_dir: Path to directory for custom nodes. + style_presets_dir: Path to directory for style presets. + workflow_thumbnails_dir: Path to directory for workflow thumbnails. log_handlers: Log handler. Valid options are "console", "file=
Valid values: `plain`, `color`, `syslog`, `legacy` log_level: Emit logging messages at this level or higher.
Valid values: `debug`, `info`, `warning`, `error`, `critical` log_sql: Log SQL queries. `log_level` must be `debug` for this to do anything. Extremely verbose. + log_level_network: Log level for network-related messages. 'info' and 'debug' are very verbose.
Valid values: `debug`, `info`, `warning`, `error`, `critical` use_memory_db: Use in-memory database. Useful for development. dev_reload: Automatically reload when Python sources are changed. Does not reload node definitions. profile_graphs: Enable graph profiling using `cProfile`. profile_prefix: An optional prefix for profile output files. profiles_dir: Path to profiles output directory. - ram: Maximum memory amount used by memory model cache for rapid switching (GB). - vram: Amount of VRAM reserved for model storage (GB). - convert_cache: Maximum size of on-disk converted models cache (GB). - lazy_offload: Keep models in VRAM until their space is needed. + max_cache_ram_gb: The maximum amount of CPU RAM to use for model caching in GB. If unset, the limit will be configured based on the available RAM. In most cases, it is recommended to leave this unset. + max_cache_vram_gb: The amount of VRAM to use for model caching in GB. If unset, the limit will be configured based on the available VRAM and the device_working_mem_gb. In most cases, it is recommended to leave this unset. log_memory_usage: If True, a memory snapshot will be captured before and after every model cache operation, and the result will be logged (at debug level). There is a time cost to capturing the memory snapshots, so it is recommended to only enable this feature if you are actively inspecting the model cache's behaviour. - device: Preferred execution device. `auto` will choose the device depending on the hardware platform and the installed torch capabilities.
Valid values: `auto`, `cpu`, `cuda`, `cuda:1`, `mps` + model_cache_keep_alive_min: How long to keep models in cache after last use, in minutes. A value of 0 (the default) means models are kept in cache indefinitely. If no model generations occur within the timeout period, the model cache is cleared using the same logic as the 'Clear Model Cache' button. + device_working_mem_gb: The amount of working memory to keep available on the compute device (in GB). Has no effect if running on CPU. If you are experiencing OOM errors, try increasing this value. + enable_partial_loading: Enable partial loading of models. This enables models to run with reduced VRAM requirements (at the cost of slower speed) by streaming the model from RAM to VRAM as its used. In some edge cases, partial loading can cause models to run more slowly if they were previously being fully loaded into VRAM. + keep_ram_copy_of_weights: Whether to keep a full RAM copy of a model's weights when the model is loaded in VRAM. Keeping a RAM copy increases average RAM usage, but speeds up model switching and LoRA patching (assuming there is sufficient RAM). Set this to False if RAM pressure is consistently high. + ram: DEPRECATED: This setting is no longer used. It has been replaced by `max_cache_ram_gb`, but most users will not need to use this config since automatic cache size limits should work well in most cases. This config setting will be removed once the new model cache behavior is stable. + vram: DEPRECATED: This setting is no longer used. It has been replaced by `max_cache_vram_gb`, but most users will not need to use this config since automatic cache size limits should work well in most cases. This config setting will be removed once the new model cache behavior is stable. + lazy_offload: DEPRECATED: This setting is no longer used. Lazy-offloading is enabled by default. This config setting will be removed once the new model cache behavior is stable. + pytorch_cuda_alloc_conf: Configure the Torch CUDA memory allocator. This will impact peak reserved VRAM usage and performance. Setting to "backend:cudaMallocAsync" works well on many systems. The optimal configuration is highly dependent on the system configuration (device type, VRAM, CUDA driver version, etc.), so must be tuned experimentally. + device: Preferred execution device. `auto` will choose the device depending on the hardware platform and the installed torch capabilities.
Valid values: `auto`, `cpu`, `cuda`, `mps`, `cuda:N` (where N is a device number) precision: Floating point precision. `float16` will consume half the memory of `float32` but produce slightly lower-quality images. The `auto` setting will guess the proper precision based on your video card and operating system.
Valid values: `auto`, `float16`, `bfloat16`, `float32` sequential_guidance: Whether to calculate guidance in serial instead of in parallel, lowering memory requirements. attention_type: Attention type.
Valid values: `auto`, `normal`, `xformers`, `sliced`, `torch-sdp` @@ -113,13 +114,26 @@ class InvokeAIAppConfig(BaseSettings): force_tiled_decode: Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty). pil_compress_level: The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = no compression, 1 = fastest with slightly larger filesize, 9 = slowest with smallest filesize. 1 is typically the best setting. max_queue_size: Maximum number of items in the session queue. - clear_queue_on_startup: Empties session queue on startup. + clear_queue_on_startup: Empties session queue on startup. If true, disables `max_queue_history`. + max_queue_history: Keep the last N completed, failed, and canceled queue items. Older items are deleted on startup. Set to 0 to prune all terminal items. Ignored if `clear_queue_on_startup` is true. allow_nodes: List of nodes to allow. Omit to allow all. deny_nodes: List of nodes to deny. Omit to deny none. node_cache_size: How many cached nodes to keep in memory. hashing_algorithm: Model hashing algorthim for model installs. 'blake3_multi' is best for SSDs. 'blake3_single' is best for spinning disk HDDs. 'random' disables hashing, instead assigning a UUID to models. Useful when using a memory db to reduce model installation time, or if you don't care about storing stable hashes for models. Alternatively, any other hashlib algorithm is accepted, though these are not nearly as performant as blake3.
Valid values: `blake3_multi`, `blake3_single`, `random`, `md5`, `sha1`, `sha224`, `sha256`, `sha384`, `sha512`, `blake2b`, `blake2s`, `sha3_224`, `sha3_256`, `sha3_384`, `sha3_512`, `shake_128`, `shake_256` remote_api_tokens: List of regular expression and token pairs used when downloading models from URLs. The download URL is tested against the regex, and if it matches, the token is provided in as a Bearer token. scan_models_on_startup: Scan the models directory on startup, registering orphaned models. This is typically only used in conjunction with `use_memory_db` for testing purposes. + unsafe_disable_picklescan: UNSAFE. Disable the picklescan security check during model installation. Recommended only for development and testing purposes. This will allow arbitrary code execution during model installation, so should never be used in production. + allow_unknown_models: Allow installation of models that we are unable to identify. If enabled, models will be marked as `unknown` in the database, and will not have any metadata associated with them. If disabled, unknown models will be rejected during installation. + multiuser: Enable multiuser support. When disabled, the application runs in single-user mode using a default system account with administrator privileges. When enabled, requires user authentication and authorization. + strict_password_checking: Enforce strict password requirements. When True, passwords must contain uppercase, lowercase, and numbers. When False (default), any password is accepted but its strength (weak/moderate/strong) is reported to the user. + external_alibabacloud_api_key: API key for Alibaba Cloud DashScope image generation. + external_alibabacloud_base_url: Base URL override for Alibaba Cloud DashScope image generation. + external_gemini_api_key: API key for Gemini image generation. + external_openai_api_key: API key for OpenAI image generation. + external_gemini_base_url: Base URL override for Gemini image generation. + external_openai_base_url: Base URL override for OpenAI image generation. + external_seedream_api_key: API key for Seedream image generation. + external_seedream_base_url: Base URL override for Seedream image generation. """ _root: Optional[Path] = PrivateAttr(default=None) @@ -139,8 +153,8 @@ class InvokeAIAppConfig(BaseSettings): allow_credentials: bool = Field(default=True, description="Allow CORS credentials.") allow_methods: list[str] = Field(default=["*"], description="Methods allowed for CORS.") allow_headers: list[str] = Field(default=["*"], description="Headers allowed for CORS.") - ssl_certfile: Optional[Path] = Field(default=None, description="SSL certificate file for HTTPS. See https://www.uvicorn.org/settings/#https.") - ssl_keyfile: Optional[Path] = Field(default=None, description="SSL key file for HTTPS. See https://www.uvicorn.org/settings/#https.") + ssl_certfile: Optional[Path] = Field(default=None, description="SSL certificate file for HTTPS. See https://www.uvicorn.dev/settings/#https.") + ssl_keyfile: Optional[Path] = Field(default=None, description="SSL key file for HTTPS. See https://www.uvicorn.dev/settings/#https.") # MISC FEATURES log_tokenization: bool = Field(default=False, description="Enable logging of parsed prompt tokens.") @@ -148,12 +162,15 @@ class InvokeAIAppConfig(BaseSettings): # PATHS models_dir: Path = Field(default=Path("models"), description="Path to the models directory.") - convert_cache_dir: Path = Field(default=Path("models/.convert_cache"), description="Path to the converted models cache directory. When loading a non-diffusers model, it will be converted and store on disk at this location.") + convert_cache_dir: Path = Field(default=Path("models/.convert_cache"), description="Path to the converted models cache directory (DEPRECATED, but do not delete because it is needed for migration from previous versions).") download_cache_dir: Path = Field(default=Path("models/.download_cache"), description="Path to the directory that contains dynamically downloaded models.") legacy_conf_dir: Path = Field(default=Path("configs"), description="Path to directory of legacy checkpoint config files.") db_dir: Path = Field(default=Path("databases"), description="Path to InvokeAI databases directory.") outputs_dir: Path = Field(default=Path("outputs"), description="Path to directory for outputs.") + image_subfolder_strategy: IMAGE_SUBFOLDER_STRATEGY = Field(default="flat", description="Strategy for organizing images into subfolders. 'flat' stores all images in a single folder. 'date' organizes by YYYY/MM/DD. 'type' organizes by image category. 'hash' uses first 2 characters of UUID for filesystem performance.") custom_nodes_dir: Path = Field(default=Path("nodes"), description="Path to directory for custom nodes.") + style_presets_dir: Path = Field(default=Path("style_presets"), description="Path to directory for style presets.") + workflow_thumbnails_dir: Path = Field(default=Path("workflow_thumbnails"), description="Path to directory for workflow thumbnails.") # LOGGING log_handlers: list[str] = Field(default=["console"], description='Log handler. Valid options are "console", "file=
Valid values: `auto`, `cpu`, `cuda`, `mps`, `cuda:N` (where N is a device number)", pattern=r"^(auto|cpu|mps|cuda(:\d+)?)$") + generation_devices: Union[Literal["auto"], list[str]] = Field(default="auto", description="Devices to use for parallel generation. `auto` (the default) uses every available GPU, running one generation session per GPU concurrently and distributing jobs fairly across users. Provide an explicit list (e.g. `[cuda:0, cuda:1]`) to use specific devices, or a single-device list (e.g. `[cuda:0]`) to run serially. On systems without a GPU, `auto` resolves to the single `cpu`/`mps` device.
Valid values: `auto`, or a list whose entries are each `cpu`, `cuda`, `mps`, or `cuda:N` (where N is a device number)") + offload_text_encoders_to_idle_gpus: bool = Field(default=True, description="When running on multiple GPUs, load text encoders onto a currently-idle GPU instead of the one running the denoise pipeline. This avoids churning the denoise model in and out of VRAM to make room for the encoder, and lets a cached encoder be reused across generations. Has no effect unless at least two `generation_devices` are configured and a GPU is idle; under full load encoders run on the session's own GPU as before.") precision: PRECISION = Field(default="auto", description="Floating point precision. `float16` will consume half the memory of `float32` but produce slightly lower-quality images. The `auto` setting will guess the proper precision based on your video card and operating system.") # GENERATION @@ -187,7 +216,8 @@ class InvokeAIAppConfig(BaseSettings): force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty).") pil_compress_level: int = Field(default=1, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = no compression, 1 = fastest with slightly larger filesize, 9 = slowest with smallest filesize. 1 is typically the best setting.") max_queue_size: int = Field(default=10000, gt=0, description="Maximum number of items in the session queue.") - clear_queue_on_startup: bool = Field(default=False, description="Empties session queue on startup.") + clear_queue_on_startup: bool = Field(default=False, description="Empties session queue on startup. If true, disables `max_queue_history`.") + max_queue_history: Optional[int] = Field(default=None, ge=0, description="Keep the last N completed, failed, and canceled queue items. Older items are deleted on startup. Set to 0 to prune all terminal items. Ignored if `clear_queue_on_startup` is true.") # NODES allow_nodes: Optional[list[str]] = Field(default=None, description="List of nodes to allow. Omit to allow all.") @@ -198,11 +228,58 @@ class InvokeAIAppConfig(BaseSettings): hashing_algorithm: HASHING_ALGORITHMS = Field(default="blake3_single", description="Model hashing algorthim for model installs. 'blake3_multi' is best for SSDs. 'blake3_single' is best for spinning disk HDDs. 'random' disables hashing, instead assigning a UUID to models. Useful when using a memory db to reduce model installation time, or if you don't care about storing stable hashes for models. Alternatively, any other hashlib algorithm is accepted, though these are not nearly as performant as blake3.") remote_api_tokens: Optional[list[URLRegexTokenPair]] = Field(default=None, description="List of regular expression and token pairs used when downloading models from URLs. The download URL is tested against the regex, and if it matches, the token is provided in as a Bearer token.") scan_models_on_startup: bool = Field(default=False, description="Scan the models directory on startup, registering orphaned models. This is typically only used in conjunction with `use_memory_db` for testing purposes.") + unsafe_disable_picklescan: bool = Field(default=False, description="UNSAFE. Disable the picklescan security check during model installation. Recommended only for development and testing purposes. This will allow arbitrary code execution during model installation, so should never be used in production.") + allow_unknown_models: bool = Field(default=True, description="Allow installation of models that we are unable to identify. If enabled, models will be marked as `unknown` in the database, and will not have any metadata associated with them. If disabled, unknown models will be rejected during installation.") + + # MULTIUSER + multiuser: bool = Field(default=False, description="Enable multiuser support. When disabled, the application runs in single-user mode using a default system account with administrator privileges. When enabled, requires user authentication and authorization.") + strict_password_checking: bool = Field(default=False, description="Enforce strict password requirements. When True, passwords must contain uppercase, lowercase, and numbers. When False (default), any password is accepted but its strength (weak/moderate/strong) is reported to the user.") + + # EXTERNAL PROVIDERS + external_alibabacloud_api_key: Optional[str] = Field(default=None, description="API key for Alibaba Cloud DashScope image generation.") + external_alibabacloud_base_url: Optional[str] = Field( + default=None, description="Base URL override for Alibaba Cloud DashScope image generation." + ) + external_gemini_api_key: Optional[str] = Field(default=None, description="API key for Gemini image generation.") + external_openai_api_key: Optional[str] = Field(default=None, description="API key for OpenAI image generation.") + external_gemini_base_url: Optional[str] = Field( + default=None, description="Base URL override for Gemini image generation." + ) + external_openai_base_url: Optional[str] = Field( + default=None, description="Base URL override for OpenAI image generation." + ) + external_seedream_api_key: Optional[str] = Field( + default=None, description="API key for Seedream image generation." + ) + external_seedream_base_url: Optional[str] = Field( + default=None, description="Base URL override for Seedream image generation." + ) # fmt: on model_config = SettingsConfigDict(env_prefix="INVOKEAI_", env_ignore_empty=True) + @field_validator("generation_devices") + @classmethod + def validate_generation_devices(cls, v: Union[str, list[str]]) -> Union[str, list[str]]: + if v == "auto": + return v + # A non-"auto" string would otherwise be iterated character-by-character below (rejecting + # 'c' from "cuda:0"), producing a confusing error. Require an explicit list instead. + if isinstance(v, str): + raise ValueError( + f"Invalid generation_devices value '{v}'. Use 'auto' or a list of devices, e.g. ['cuda:0', 'cuda:1']." + ) + if len(v) == 0: + raise ValueError("generation_devices cannot be an empty list. Use 'auto' or a list of devices.") + pattern = re.compile(r"^(cpu|mps|cuda(:\d+)?)$") + for device in v: + if not pattern.match(device): + raise ValueError( + f"Invalid generation device '{device}'. Valid values are 'auto', 'cpu', 'mps', 'cuda', or 'cuda:N'." + ) + return v + def update_config(self, config: dict[str, Any] | InvokeAIAppConfig, clobber: bool = True) -> None: """Updates the config, overwriting existing values. @@ -250,13 +327,13 @@ def write_file(self, dest_path: Path, as_example: bool = False) -> None: ) if as_example: - file.write( - "# This is an example file with default and example settings. Use the values here as a baseline.\n\n" - ) + file.write("# This is an example file with default and example settings.\n") + file.write("# You should not copy this whole file into your config.\n") + file.write("# Only add the settings you need to change to your config file.\n\n") file.write("# Internal metadata - do not edit:\n") file.write(yaml.dump(meta_dict, sort_keys=False)) file.write("\n") - file.write("# Put user settings here - see https://invoke-ai.github.io/InvokeAI/features/CONFIGURATION/:\n") + file.write("# Put user settings here - see https://invoke.ai/configuration/invokeai-yaml/:\n") if len(config_dict) > 0: file.write(yaml.dump(config_dict, sort_keys=False)) @@ -280,6 +357,13 @@ def config_file_path(self) -> Path: assert resolved_path is not None return resolved_path + @property + def api_keys_file_path(self) -> Path: + """Path to api_keys.yaml, resolved to an absolute path..""" + resolved_path = self._resolve(API_KEYS_FILE) + assert resolved_path is not None + return resolved_path + @property def outputs_path(self) -> Optional[Path]: """Path to the outputs directory, resolved to an absolute path..""" @@ -302,6 +386,16 @@ def models_path(self) -> Path: """Path to the models directory, resolved to an absolute path..""" return self._resolve(self.models_dir) + @property + def style_presets_path(self) -> Path: + """Path to the style presets directory, resolved to an absolute path..""" + return self._resolve(self.style_presets_dir) + + @property + def workflow_thumbnails_path(self) -> Path: + """Path to the workflow thumbnails directory, resolved to an absolute path..""" + return self._resolve(self.workflow_thumbnails_dir) + @property def convert_cache_path(self) -> Path: """Path to the converted cache models directory, resolved to an absolute path..""" @@ -357,14 +451,14 @@ def settings_customise_sources( return (init_settings,) -def migrate_v3_config_dict(config_dict: dict[str, Any]) -> InvokeAIAppConfig: - """Migrate a v3 config dictionary to a current config object. +def migrate_v3_config_dict(config_dict: dict[str, Any]) -> dict[str, Any]: + """Migrate a v3 config dictionary to a v4.0.0. Args: config_dict: A dictionary of settings from a v3 config file. Returns: - An instance of `InvokeAIAppConfig` with the migrated settings. + An `InvokeAIAppConfig` config dict. """ parsed_config_dict: dict[str, Any] = {} @@ -398,32 +492,55 @@ def migrate_v3_config_dict(config_dict: dict[str, Any]) -> InvokeAIAppConfig: elif k in InvokeAIAppConfig.model_fields: # skip unknown fields parsed_config_dict[k] = v - # When migrating the config file, we should not include currently-set environment variables. - config = DefaultInvokeAIAppConfig.model_validate(parsed_config_dict) - - return config + parsed_config_dict["schema_version"] = "4.0.0" + return parsed_config_dict -def migrate_v4_0_0_config_dict(config_dict: dict[str, Any]) -> InvokeAIAppConfig: - """Migrate v4.0.0 config dictionary to a current config object. +def migrate_v4_0_0_to_4_0_1_config_dict(config_dict: dict[str, Any]) -> dict[str, Any]: + """Migrate v4.0.0 config dictionary to a v4.0.1 config dictionary Args: config_dict: A dictionary of settings from a v4.0.0 config file. Returns: - An instance of `InvokeAIAppConfig` with the migrated settings. + A config dict with the settings migrated to v4.0.1. """ - parsed_config_dict: dict[str, Any] = {} - for k, v in config_dict.items(): - # autocast was removed from precision in v4.0.1 - if k == "precision" and v == "autocast": - parsed_config_dict["precision"] = "auto" - else: - parsed_config_dict[k] = v - if k == "schema_version": - parsed_config_dict[k] = CONFIG_SCHEMA_VERSION - config = DefaultInvokeAIAppConfig.model_validate(parsed_config_dict) - return config + parsed_config_dict: dict[str, Any] = copy.deepcopy(config_dict) + # precision "autocast" was replaced by "auto" in v4.0.1 + if parsed_config_dict.get("precision") == "autocast": + parsed_config_dict["precision"] = "auto" + parsed_config_dict["schema_version"] = "4.0.1" + return parsed_config_dict + + +def migrate_v4_0_1_to_4_0_2_config_dict(config_dict: dict[str, Any]) -> dict[str, Any]: + """Migrate v4.0.1 config dictionary to a v4.0.2 config dictionary. + + Args: + config_dict: A dictionary of settings from a v4.0.1 config file. + + Returns: + An config dict with the settings migrated to v4.0.2. + """ + parsed_config_dict: dict[str, Any] = copy.deepcopy(config_dict) + # convert_cache was removed in 4.0.2 + parsed_config_dict.pop("convert_cache", None) + parsed_config_dict["schema_version"] = "4.0.2" + return parsed_config_dict + + +def migrate_v4_0_2_to_4_0_3_config_dict(config_dict: dict[str, Any]) -> dict[str, Any]: + """Migrate v4.0.2 config dictionary to a v4.0.3 config dictionary. + + Args: + config_dict: A dictionary of settings from a v4.0.2 config file. + + Returns: + A config dict with the settings migrated to v4.0.3. + """ + parsed_config_dict: dict[str, Any] = copy.deepcopy(config_dict) + parsed_config_dict["schema_version"] = "4.0.3" + return parsed_config_dict def load_and_migrate_config(config_path: Path) -> InvokeAIAppConfig: @@ -437,38 +554,75 @@ def load_and_migrate_config(config_path: Path) -> InvokeAIAppConfig: """ assert config_path.suffix == ".yaml" with open(config_path, "rt", encoding=locale.getpreferredencoding()) as file: - loaded_config_dict = yaml.safe_load(file) + loaded_config_dict: dict[str, Any] = yaml.safe_load(file) assert isinstance(loaded_config_dict, dict) + migrated = False if "InvokeAI" in loaded_config_dict: - # This is a v3 config file, attempt to migrate it + migrated = True + loaded_config_dict = migrate_v3_config_dict(loaded_config_dict) # pyright: ignore [reportUnknownArgumentType] + if loaded_config_dict["schema_version"] == "4.0.0": + migrated = True + loaded_config_dict = migrate_v4_0_0_to_4_0_1_config_dict(loaded_config_dict) + if loaded_config_dict["schema_version"] == "4.0.1": + migrated = True + loaded_config_dict = migrate_v4_0_1_to_4_0_2_config_dict(loaded_config_dict) + if loaded_config_dict["schema_version"] == "4.0.2": + migrated = True + loaded_config_dict = migrate_v4_0_2_to_4_0_3_config_dict(loaded_config_dict) + + if migrated: shutil.copy(config_path, config_path.with_suffix(".yaml.bak")) try: - # loaded_config_dict could be the wrong shape, but we will catch all exceptions below - migrated_config = migrate_v3_config_dict(loaded_config_dict) # pyright: ignore [reportUnknownArgumentType] + # load and write without environment variables + migrated_config = DefaultInvokeAIAppConfig.model_validate(loaded_config_dict) + migrated_config.write_file(config_path) except Exception as e: shutil.copy(config_path.with_suffix(".yaml.bak"), config_path) raise RuntimeError(f"Failed to load and migrate v3 config file {config_path}: {e}") from e - migrated_config.write_file(config_path) - return migrated_config - if loaded_config_dict["schema_version"] == "4.0.0": - loaded_config_dict = migrate_v4_0_0_config_dict(loaded_config_dict) - loaded_config_dict.write_file(config_path) - - # Attempt to load as a v4 config file try: # Meta is not included in the model fields, so we need to validate it separately config = InvokeAIAppConfig.model_validate(loaded_config_dict) - assert ( - config.schema_version == CONFIG_SCHEMA_VERSION - ), f"Invalid schema version, expected {CONFIG_SCHEMA_VERSION}: {config.schema_version}" + assert config.schema_version == CONFIG_SCHEMA_VERSION, ( + f"Invalid schema version, expected {CONFIG_SCHEMA_VERSION}: {config.schema_version}" + ) return config except Exception as e: raise RuntimeError(f"Failed to load config file {config_path}: {e}") from e +def load_external_api_keys(api_keys_file_path: Path) -> dict[str, str]: + """Load external provider config (API keys and base URLs) from a dedicated YAML file.""" + if not api_keys_file_path.exists(): + return {} + + with open(api_keys_file_path, "rt", encoding=locale.getpreferredencoding()) as file: + loaded_api_keys: Any = yaml.safe_load(file) + + if loaded_api_keys is None: + return {} + + if not isinstance(loaded_api_keys, dict): + raise RuntimeError(f"Failed to load api keys file {api_keys_file_path}: expected a mapping") + + parsed_api_keys: dict[str, str] = {} + for field_name in EXTERNAL_PROVIDER_CONFIG_FIELDS: + value = loaded_api_keys.get(field_name) + if value is None: + continue + if not isinstance(value, str): + raise RuntimeError( + f"Failed to load api keys file {api_keys_file_path}: value for '{field_name}' must be a string" + ) + stripped_value = value.strip() + if stripped_value: + parsed_api_keys[field_name] = stripped_value + + return parsed_api_keys + + @lru_cache(maxsize=1) def get_config() -> InvokeAIAppConfig: """Get the global singleton app config. @@ -485,6 +639,7 @@ def get_config() -> InvokeAIAppConfig: """ # This object includes environment variables, as parsed by pydantic-settings config = InvokeAIAppConfig() + env_fields_set = set(config.model_fields_set) args = InvokeAIArgs.args @@ -507,9 +662,35 @@ def get_config() -> InvokeAIAppConfig: ] example_config.write_file(config.config_file_path.with_suffix(".example.yaml"), as_example=True) - # Copy all legacy configs - We know `__path__[0]` is correct here + # Copy all legacy configs only if needed + # We know `__path__[0]` is correct here configs_src = Path(model_configs.__path__[0]) # pyright: ignore [reportUnknownMemberType, reportUnknownArgumentType, reportAttributeAccessIssue] - shutil.copytree(configs_src, config.legacy_conf_path, dirs_exist_ok=True) + dest_path = config.legacy_conf_path + + # Create destination (we don't need to check for existence) + dest_path.mkdir(parents=True, exist_ok=True) + + # Compare directories recursively + comparison = filecmp.dircmp(configs_src, dest_path) + need_copy = any( + [ + comparison.left_only, # Files exist only in source + comparison.diff_files, # Files that differ + comparison.common_funny, # Files that couldn't be compared + ] + ) + + if need_copy: + # Get permissions from destination directory + dest_mode = dest_path.stat().st_mode + + # Copy directory tree + shutil.copytree(configs_src, dest_path, dirs_exist_ok=True) + + # Set permissions on copied files to match destination directory + dest_path.chmod(dest_mode) + for p in dest_path.glob("**/*"): + p.chmod(dest_mode) if config.config_file_path.exists(): config_from_file = load_and_migrate_config(config.config_file_path) @@ -520,4 +701,11 @@ def get_config() -> InvokeAIAppConfig: default_config = DefaultInvokeAIAppConfig() default_config.write_file(config.config_file_path, as_example=False) + api_keys_from_file = load_external_api_keys(config.api_keys_file_path) + if api_keys_from_file: + # API keys file should take precedence over invokeai.yaml, but not over environment variables. + api_keys_to_apply = {key: value for key, value in api_keys_from_file.items() if key not in env_fields_set} + if api_keys_to_apply: + config.update_config(api_keys_to_apply, clobber=True) + return config diff --git a/invokeai/app/services/download/__init__.py b/invokeai/app/services/download/__init__.py index 33b0025809c..48ded7d5496 100644 --- a/invokeai/app/services/download/__init__.py +++ b/invokeai/app/services/download/__init__.py @@ -1,13 +1,13 @@ """Init file for download queue.""" -from .download_base import ( +from invokeai.app.services.download.download_base import ( DownloadJob, DownloadJobStatus, DownloadQueueServiceBase, MultiFileDownloadJob, UnknownJobIDException, ) -from .download_default import DownloadQueueService, TqdmProgress +from invokeai.app.services.download.download_default import DownloadQueueService, TqdmProgress __all__ = [ "DownloadJob", diff --git a/invokeai/app/services/download/download_base.py b/invokeai/app/services/download/download_base.py index 4880ab98b89..1798fd69df5 100644 --- a/invokeai/app/services/download/download_base.py +++ b/invokeai/app/services/download/download_base.py @@ -18,6 +18,7 @@ class DownloadJobStatus(str, Enum): WAITING = "waiting" # not enqueued, will not run RUNNING = "running" # actively downloading + PAUSED = "paused" # paused, can be resumed COMPLETED = "completed" # finished running CANCELLED = "cancelled" # user cancelled ERROR = "error" # terminated with an error message @@ -61,6 +62,7 @@ class DownloadJobBase(BaseModel): # internal flag _cancelled: bool = PrivateAttr(default=False) + _paused: bool = PrivateAttr(default=False) # optional event handlers passed in on creation _on_start: Optional[DownloadEventHandler] = PrivateAttr(default=None) @@ -72,6 +74,12 @@ class DownloadJobBase(BaseModel): def cancel(self) -> None: """Call to cancel the job.""" self._cancelled = True + self._paused = False + + def pause(self) -> None: + """Pause the job, preserving partial downloads.""" + self._paused = True + self._cancelled = True # cancelled and the callbacks are private attributes in order to prevent # them from being serialized and/or used in the Json Schema @@ -80,6 +88,11 @@ def cancelled(self) -> bool: """Call to cancel the job.""" return self._cancelled + @property + def paused(self) -> bool: + """Return true if job is paused.""" + return self._paused + @property def complete(self) -> bool: """Return true if job completed without errors.""" @@ -161,6 +174,17 @@ class DownloadJob(DownloadJobBase): default=None, description="Timestamp for when the download job ende1d (completed or errored)" ) content_type: Optional[str] = Field(default=None, description="Content type of downloaded file") + canonical_url: Optional[str] = Field(default=None, description="Canonical URL to request on resume") + etag: Optional[str] = Field(default=None, description="ETag from the remote server, if available") + last_modified: Optional[str] = Field(default=None, description="Last-Modified from the remote server, if available") + final_url: Optional[str] = Field(default=None, description="Final resolved URL after redirects, if available") + expected_total_bytes: Optional[int] = Field(default=None, description="Expected total size of the download") + resume_required: bool = Field(default=False, description="True if server refused resume; restart required") + resume_message: Optional[str] = Field(default=None, description="Message explaining why resume is required") + resume_from_scratch: bool = Field( + default=False, + description="True if resume metadata existed but the partial file was missing and the download restarted from the beginning", + ) def __hash__(self) -> int: """Return hash of the string representation of this object, for indexing.""" @@ -321,6 +345,10 @@ def cancel_job(self, job: DownloadJobBase) -> None: """Cancel the job, clearing partial downloads and putting it into ERROR state.""" pass + def pause_job(self, job: DownloadJobBase) -> None: # noqa D401 + """Pause the job, preserving partial downloads.""" + raise NotImplementedError + @abstractmethod def join(self) -> None: """Wait until all jobs are off the queue.""" diff --git a/invokeai/app/services/download/download_default.py b/invokeai/app/services/download/download_default.py index f6c7c1a1a0c..13e86d18284 100644 --- a/invokeai/app/services/download/download_default.py +++ b/invokeai/app/services/download/download_default.py @@ -1,4 +1,4 @@ -# Copyright (c) 2023, Lincoln D. Stein +# Copyright (c) 2023,2026 Lincoln D. Stein """Implementation of multithreaded download queue for invokeai.""" import os @@ -8,7 +8,9 @@ import traceback from pathlib import Path from queue import Empty, PriorityQueue -from typing import Any, Dict, List, Literal, Optional, Set +from shutil import disk_usage +from typing import TYPE_CHECKING, Any, Dict, List, Literal, Optional, Set +from urllib.parse import urlparse import requests from pydantic.networks import AnyHttpUrl @@ -16,12 +18,7 @@ from tqdm import tqdm from invokeai.app.services.config import InvokeAIAppConfig, get_config -from invokeai.app.services.events.events_base import EventServiceBase -from invokeai.app.util.misc import get_iso_timestamp -from invokeai.backend.model_manager.metadata import RemoteModelFile -from invokeai.backend.util.logging import InvokeAILogger - -from .download_base import ( +from invokeai.app.services.download.download_base import ( DownloadEventHandler, DownloadExceptionHandler, DownloadJob, @@ -33,6 +30,12 @@ ServiceInactiveException, UnknownJobIDException, ) +from invokeai.app.util.misc import get_iso_timestamp +from invokeai.backend.model_manager.metadata import RemoteModelFile +from invokeai.backend.util.logging import InvokeAILogger + +if TYPE_CHECKING: + from invokeai.app.services.events.events_base import EventServiceBase # Maximum number of bytes to download during each call to requests.iter_content() DOWNLOAD_CHUNK_SIZE = 100000 @@ -57,7 +60,9 @@ def __init__( """ self._app_config = app_config or get_config() self._jobs: Dict[int, DownloadJob] = {} - self._download_part2parent: Dict[AnyHttpUrl, MultiFileDownloadJob] = {} + self._download_part2parent: Dict[int, MultiFileDownloadJob] = {} + self._mfd_pending: Dict[int, list[DownloadJob]] = {} + self._mfd_active: Dict[int, DownloadJob] = {} self._next_job_id = 0 self._queue: PriorityQueue[DownloadJob] = PriorityQueue() self._stop_event = threading.Event() @@ -83,7 +88,7 @@ def stop(self, *args: Any, **kwargs: Any) -> None: """Stop the download worker threads.""" with self._lock: if not self._worker_pool: - raise Exception("Attempt to stop the download service before it was started") + return self._accept_download_requests = False # reject attempts to add new jobs to queue queued_jobs = [x for x in self.list_jobs() if x.status == DownloadJobStatus.WAITING] active_jobs = [x for x in self.list_jobs() if x.status == DownloadJobStatus.RUNNING] @@ -113,7 +118,8 @@ def submit_download_job( raise ServiceInactiveException( "The download service is not currently accepting requests. Please call start() to initialize the service." ) - job.id = self._next_id() + if job.id == -1: + job.id = self._next_id() job.set_callbacks( on_start=on_start, on_progress=on_progress, @@ -124,6 +130,11 @@ def submit_download_job( self._jobs[job.id] = job self._queue.put(job) + def pause_job(self, job: DownloadJobBase) -> None: + """Pause the indicated job, preserving partial downloads.""" + if job.status in [DownloadJobStatus.WAITING, DownloadJobStatus.RUNNING]: + job.pause() + def download( self, source: AnyHttpUrl, @@ -185,24 +196,41 @@ def multifile_download( job = DownloadJob( source=url, dest=path, - access_token=access_token, + access_token=access_token or self._lookup_access_token(url), ) + job.id = self._next_id() # pre-assign ID so _download_part2parent can be keyed by ID + if part.size and part.size > 0: + job.total_bytes = part.size + job.expected_total_bytes = part.size + job.canonical_url = str(url) mfdj.download_parts.add(job) - self._download_part2parent[job.source] = mfdj + self._download_part2parent[job.id] = mfdj if submit_job: self.submit_multifile_download(mfdj) return mfdj def submit_multifile_download(self, job: MultiFileDownloadJob) -> None: - for download_job in job.download_parts: - self.submit_download_job( - download_job, - on_start=self._mfd_started, - on_progress=self._mfd_progress, - on_complete=self._mfd_complete, - on_cancelled=self._mfd_cancelled, - on_error=self._mfd_error, - ) + pending = sorted(job.download_parts, key=lambda j: str(j.source)) + self._mfd_pending[job.id] = list(pending) + self._mfd_active.pop(job.id, None) + self._submit_next_mfd_part(job) + + def _submit_next_mfd_part(self, job: MultiFileDownloadJob) -> None: + pending = self._mfd_pending.get(job.id, []) + if not pending: + return + if self._mfd_active.get(job.id) is not None: + return + download_job = pending.pop(0) + self._mfd_active[job.id] = download_job + self.submit_download_job( + download_job, + on_start=self._mfd_started, + on_progress=self._mfd_progress, + on_complete=self._mfd_complete, + on_cancelled=self._mfd_cancelled, + on_error=self._mfd_error, + ) def join(self) -> None: """Wait for all jobs to complete.""" @@ -282,12 +310,18 @@ def _download_next_item(self) -> None: except Empty: continue try: + if job.cancelled: + raise DownloadJobCancelledException("Job was cancelled before start") job.job_started = get_iso_timestamp() self._do_download(job) - self._signal_job_complete(job) + if job.status != DownloadJobStatus.COMPLETED: + self._signal_job_complete(job) except DownloadJobCancelledException: - self._signal_job_cancelled(job) - self._cleanup_cancelled_job(job) + if job.paused: + self._signal_job_paused(job) + else: + self._signal_job_cancelled(job) + self._cleanup_cancelled_job(job) except Exception as excp: job.error_type = excp.__class__.__name__ + f"({str(excp)})" job.error = traceback.format_exc() @@ -295,8 +329,7 @@ def _download_next_item(self) -> None: finally: job.job_ended = get_iso_timestamp() self._job_terminated_event.set() # signal a change to terminal state - self._download_part2parent.pop(job.source, None) # if this is a subpart of a multipart job, remove it - self._job_terminated_event.set() + self._download_part2parent.pop(job.id, None) # if this is a subpart of a multipart job, remove it self._queue.task_done() self._logger.debug(f"Download queue worker thread {threading.current_thread().name} exiting.") @@ -304,22 +337,130 @@ def _download_next_item(self) -> None: def _do_download(self, job: DownloadJob) -> None: """Do the actual download.""" - url = job.source + url = job.canonical_url or str(job.source) header = {"Authorization": f"Bearer {job.access_token}"} if job.access_token else {} + had_resume_metadata = bool(job.etag or job.last_modified) open_mode = "wb" + resume_from = 0 + + if not job.dest.is_dir(): + job.download_path = job.dest + in_progress_path = self._in_progress_path(job.download_path) + if in_progress_path.exists(): + resume_from = in_progress_path.stat().st_size + job.bytes = resume_from + self._logger.debug( + f"Resume check: in-progress file found at {in_progress_path} size={resume_from} bytes" + ) + if resume_from > 0: + if job.etag: + header["If-Range"] = job.etag + elif job.last_modified: + header["If-Range"] = job.last_modified + header["Range"] = f"bytes={resume_from}-" + open_mode = "ab" + else: + self._logger.debug(f"Resume check: no in-progress file at {in_progress_path}") + elif job.download_path: + # Resume for directory downloads when we already know the filename. + in_progress_path = self._in_progress_path(job.download_path) + if in_progress_path.exists(): + resume_from = in_progress_path.stat().st_size + job.bytes = resume_from + self._logger.debug( + f"Resume check (dir): in-progress file found at {in_progress_path} size={resume_from} bytes" + ) + if resume_from > 0: + if job.etag: + header["If-Range"] = job.etag + elif job.last_modified: + header["If-Range"] = job.last_modified + header["Range"] = f"bytes={resume_from}-" + open_mode = "ab" + else: + self._logger.debug(f"Resume check (dir): no in-progress file at {in_progress_path}") + elif job.dest.is_dir(): + # Attempt to infer a single in-progress file from disk for directory downloads. + try: + candidates = sorted(job.dest.glob("*.downloading")) + except OSError: + candidates = [] + if len(candidates) == 1: + inferred = candidates[0].with_name(candidates[0].name.removesuffix(".downloading")) + job.download_path = inferred + try: + resume_from = candidates[0].stat().st_size + except FileNotFoundError: + # The .downloading file was renamed/deleted between glob and stat (race condition); skip resume. + job.download_path = None + else: + job.bytes = resume_from + self._logger.debug( + f"Resume check (dir): inferred in-progress file path={candidates[0]} size={resume_from} bytes" + ) + if resume_from > 0: + if job.etag: + header["If-Range"] = job.etag + elif job.last_modified: + header["If-Range"] = job.last_modified + header["Range"] = f"bytes={resume_from}-" + open_mode = "ab" + else: + self._logger.debug( + "Resume check (dir): no prior download_path available; cannot resume from disk " + f"(candidates={len(candidates)})" + ) + + if resume_from == 0: + job.bytes = 0 + if had_resume_metadata: + job.resume_from_scratch = True + job.resume_message = "Partial file missing. Restarted download from the beginning." # Make a streaming request. This will retrieve headers including # content-length and content-disposition, but not fetch any content itself resp = self._requests.get(str(url), headers=header, stream=True) + job.final_url = str(resp.url) if resp.url else None + self._logger.debug( + "Resume response: " + f"status={resp.status_code} " + f"content_length={resp.headers.get('content-length')} " + f"content_range={resp.headers.get('Content-Range')} " + f"etag={resp.headers.get('ETag')} " + f"last_modified={resp.headers.get('Last-Modified')}" + ) + if resp.status_code == 416 and resume_from > 0: + # Range not satisfiable - local partial is already complete + expected = job.expected_total_bytes or job.total_bytes or resume_from + if resume_from == expected: + job.total_bytes = expected + job.bytes = resume_from + job.download_path = job.download_path or job.dest + self._signal_job_started(job) + self._signal_job_complete(job) + return + job.resume_required = True + job.resume_message = "Resume refused by server. Restart required." + job.pause() + raise DownloadJobCancelledException("Resume refused by server. Restart required.") if not resp.ok: - raise HTTPError(resp.reason) + host = urlparse(str(resp.url or url)).netloc + status = resp.status_code + reason = resp.reason + if status >= 500: + self._logger.error(f"Remote server error from {host}: HTTP {status} {reason}") + raise HTTPError(reason) + self._logger.error(f"Download failed from {host}: HTTP {status} {reason}") + raise HTTPError(reason) job.content_type = resp.headers.get("Content-Type") + job.etag = resp.headers.get("ETag") or job.etag + job.last_modified = resp.headers.get("Last-Modified") or job.last_modified content_length = int(resp.headers.get("content-length", 0)) - job.total_bytes = content_length if job.dest.is_dir(): - file_name = os.path.basename(str(url.path)) # default is to use the last bit of the URL + parsed_url = urlparse(str(url)) + file_name = os.path.basename(parsed_url.path) # default is to use the last bit of the URL if match := re.search('filename="(.+)"', resp.headers.get("Content-Disposition", "")): remote_name = match.group(1) @@ -334,31 +475,83 @@ def _do_download(self, job: DownloadJob) -> None: assert job.download_path + in_progress_path = self._in_progress_path(job.download_path) + + if resume_from > 0 and resp.status_code == 200: + # Server ignored Range. Restart download from scratch. + job.resume_required = True + job.resume_message = "Resume refused by server. Restart required." + job.pause() + raise DownloadJobCancelledException("Resume refused by server. Restart required.") + + if resume_from > 0 and resp.status_code == 206: + content_range = resp.headers.get("Content-Range", "") + total_from_range = None + if match := re.match(r"bytes\s+\d+-\d+/(\d+)", content_range): + total_from_range = int(match.group(1)) + if total_from_range is not None: + job.total_bytes = total_from_range + else: + job.total_bytes = resume_from + content_length + job.bytes = resume_from + job.expected_total_bytes = job.total_bytes + else: + job.total_bytes = content_length + job.expected_total_bytes = content_length + + if job.download_path.exists() and resume_from == 0: + existing_size = job.download_path.stat().st_size + if job.total_bytes > 0 and existing_size == job.total_bytes: + job.bytes = existing_size + self._signal_job_started(job) + self._signal_job_complete(job) + return + # Existing file does not match expected size; treat as corrupt and restart. + self._logger.debug( + "Resume check: existing file size mismatch; deleting and restarting " + f"path={job.download_path} existing_size={existing_size} expected={job.total_bytes}" + ) + job.download_path.unlink() + + free_space = disk_usage(job.download_path.parent).free + GB = 2**30 + remaining_bytes = max(job.total_bytes - job.bytes, 0) + if free_space < remaining_bytes: + raise RuntimeError( + f"Free disk space {free_space / GB:.2f} GB is not enough for download of {remaining_bytes / GB:.2f} GB." + ) + # Don't clobber an existing file. See commit 82c2c85202f88c6d24ff84710f297cfc6ae174af # for code that instead resumes an interrupted download. - if job.download_path.exists(): + if job.download_path.exists() and resume_from == 0: raise OSError(f"[Errno 17] File {job.download_path} exists") # append ".downloading" to the path - in_progress_path = self._in_progress_path(job.download_path) - # signal caller that the download is starting. At this point, key fields such as # download_path and total_bytes will be populated. We call it here because the might # discover that the local file is already complete and generate a COMPLETED status. self._signal_job_started(job) + expected_total = job.total_bytes or job.expected_total_bytes or content_length # "range not satisfiable" - local file is at least as large as the remote file - if resp.status_code == 416 or (content_length > 0 and job.bytes >= content_length): - self._logger.warning(f"{job.download_path}: complete file found. Skipping.") + if resp.status_code == 416 or (expected_total > 0 and job.bytes >= expected_total): + self._logger.info(f"{job.download_path}: complete file found. Skipping.") return # "partial content" - local file is smaller than remote file elif resp.status_code == 206 or job.bytes > 0: - self._logger.warning(f"{job.download_path}: partial file found. Resuming") + self._logger.info(f"{job.download_path}: partial file found. Resuming") # some other error elif resp.status_code != 200: - raise HTTPError(resp.reason) + host = urlparse(str(resp.url or url)).netloc + status = resp.status_code + reason = resp.reason + if status >= 500: + self._logger.error(f"Remote server error from {host}: HTTP {status} {reason}") + raise HTTPError(reason) + self._logger.error(f"Download failed from {host}: HTTP {status} {reason}") + raise HTTPError(reason) self._logger.debug(f"{job.source}: Downloading {job.download_path}") report_delta = job.total_bytes / 100 # report every 1% change @@ -375,6 +568,12 @@ def _do_download(self, job: DownloadJob) -> None: last_report_bytes = job.bytes self._signal_job_progress(job) + if job.total_bytes > 0 and job.bytes < job.total_bytes: + job.resume_required = True + job.resume_message = "Download interrupted. Resume required." + job.pause() + raise DownloadJobCancelledException("Download interrupted. Resume required.") + # if we get here we are done and can rename the file to the original dest self._logger.debug(f"{job.source}: saved to {job.download_path} (bytes={job.bytes})") in_progress_path.rename(job.download_path) @@ -430,11 +629,28 @@ def _signal_job_cancelled(self, job: DownloadJob) -> None: self._event_bus.emit_download_cancelled(job) # if multifile download, then signal the parent - if parent_job := self._download_part2parent.get(job.source, None): + if parent_job := self._download_part2parent.get(job.id, None): if not parent_job.in_terminal_state: parent_job.status = DownloadJobStatus.CANCELLED self._execute_cb(parent_job, "on_cancelled") + def _signal_job_paused(self, job: DownloadJob) -> None: + if job.status not in [DownloadJobStatus.RUNNING, DownloadJobStatus.WAITING]: + return + if job.download_path: + in_progress_path = self._in_progress_path(job.download_path) + if in_progress_path.exists(): + job.bytes = in_progress_path.stat().st_size + job.status = DownloadJobStatus.PAUSED + self._execute_cb(job, "on_cancelled") + if self._event_bus: + self._event_bus.emit_download_paused(job) + + if parent_job := self._download_part2parent.get(job.id, None): + if not parent_job.in_terminal_state: + parent_job.status = DownloadJobStatus.PAUSED + self._execute_cb(parent_job, "on_cancelled") + def _signal_job_error(self, job: DownloadJob, excp: Optional[Exception] = None) -> None: job.status = DownloadJobStatus.ERROR self._logger.error(f"{str(job.source)}: {traceback.format_exception(excp)}") @@ -444,6 +660,8 @@ def _signal_job_error(self, job: DownloadJob, excp: Optional[Exception] = None) self._event_bus.emit_download_error(job) def _cleanup_cancelled_job(self, job: DownloadJob) -> None: + if job.paused: + return self._logger.debug(f"Cleaning up leftover files from cancelled download job {job.download_path}") try: if job.download_path: @@ -458,7 +676,7 @@ def _cleanup_cancelled_job(self, job: DownloadJob) -> None: def _mfd_started(self, download_job: DownloadJob) -> None: self._logger.info(f"File download started: {download_job.source}") with self._lock: - mf_job = self._download_part2parent[download_job.source] + mf_job = self._download_part2parent[download_job.id] if mf_job.waiting: mf_job.total_bytes = sum(x.total_bytes for x in mf_job.download_parts) mf_job.status = DownloadJobStatus.RUNNING @@ -471,44 +689,62 @@ def _mfd_started(self, download_job: DownloadJob) -> None: def _mfd_progress(self, download_job: DownloadJob) -> None: with self._lock: - mf_job = self._download_part2parent[download_job.source] + mf_job = self._download_part2parent[download_job.id] if mf_job.cancelled: for part in mf_job.download_parts: self.cancel_job(part) elif mf_job.running: mf_job.total_bytes = sum(x.total_bytes for x in mf_job.download_parts) - mf_job.bytes = sum(x.total_bytes for x in mf_job.download_parts) + mf_job.bytes = sum(x.bytes for x in mf_job.download_parts) self._execute_cb(mf_job, "on_progress") def _mfd_complete(self, download_job: DownloadJob) -> None: self._logger.info(f"Download complete: {download_job.source}") + submit_next = False + mf_job: Optional[MultiFileDownloadJob] = None with self._lock: - mf_job = self._download_part2parent[download_job.source] + mf_job = self._download_part2parent[download_job.id] + self._mfd_active.pop(mf_job.id, None) + mf_job.total_bytes = sum(x.total_bytes for x in mf_job.download_parts) + mf_job.bytes = sum(x.bytes for x in mf_job.download_parts) # are there any more active jobs left in this task? - if mf_job.running and all(x.complete for x in mf_job.download_parts): + if all(x.complete for x in mf_job.download_parts): mf_job.status = DownloadJobStatus.COMPLETED self._execute_cb(mf_job, "on_complete") + elif not mf_job.in_terminal_state and not mf_job.paused: + submit_next = True # we're done with this sub-job self._job_terminated_event.set() + if submit_next and mf_job is not None: + self._submit_next_mfd_part(mf_job) def _mfd_cancelled(self, download_job: DownloadJob) -> None: with self._lock: - mf_job = self._download_part2parent[download_job.source] + mf_job = self._download_part2parent[download_job.id] assert mf_job is not None + self._mfd_active.pop(mf_job.id, None) if not mf_job.in_terminal_state: - self._logger.warning(f"Download cancelled: {download_job.source}") - mf_job.cancel() - + if download_job.paused: + self._logger.warning(f"Download paused: {download_job.source}") + mf_job.pause() + else: + self._logger.warning(f"Download cancelled: {download_job.source}") + mf_job.cancel() + + if download_job.paused: + return for s in mf_job.download_parts: self.cancel_job(s) + self._mfd_pending.pop(mf_job.id, None) def _mfd_error(self, download_job: DownloadJob, excp: Optional[Exception] = None) -> None: with self._lock: - mf_job = self._download_part2parent[download_job.source] + mf_job = self._download_part2parent[download_job.id] assert mf_job is not None + self._mfd_active.pop(mf_job.id, None) if not mf_job.in_terminal_state: mf_job.status = download_job.status mf_job.error = download_job.error @@ -519,7 +755,7 @@ def _mfd_error(self, download_job: DownloadJob, excp: Optional[Exception] = None ) for s in [x for x in mf_job.download_parts if x.running]: self.cancel_job(s) - self._download_part2parent.pop(download_job.source) + self._mfd_pending.pop(mf_job.id, None) self._job_terminated_event.set() def _execute_cb( diff --git a/invokeai/app/services/events/__init__.py b/invokeai/app/services/events/__init__.py index 17407d3b72a..e69de29bb2d 100644 --- a/invokeai/app/services/events/__init__.py +++ b/invokeai/app/services/events/__init__.py @@ -1 +0,0 @@ -from .events_base import EventServiceBase # noqa F401 diff --git a/invokeai/app/services/events/events_base.py b/invokeai/app/services/events/events_base.py index bb578c23e8c..935b422a732 100644 --- a/invokeai/app/services/events/events_base.py +++ b/invokeai/app/services/events/events_base.py @@ -11,12 +11,13 @@ DownloadCancelledEvent, DownloadCompleteEvent, DownloadErrorEvent, + DownloadPausedEvent, DownloadProgressEvent, DownloadStartedEvent, EventBase, InvocationCompleteEvent, - InvocationDenoiseProgressEvent, InvocationErrorEvent, + InvocationProgressEvent, InvocationStartedEvent, ModelInstallCancelledEvent, ModelInstallCompleteEvent, @@ -28,9 +29,10 @@ ModelLoadCompleteEvent, ModelLoadStartedEvent, QueueClearedEvent, + QueueItemsRetriedEvent, QueueItemStatusChangedEvent, + RecallParametersUpdatedEvent, ) -from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState if TYPE_CHECKING: from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput @@ -40,10 +42,12 @@ from invokeai.app.services.session_queue.session_queue_common import ( BatchStatus, EnqueueBatchResult, + RetryItemsResult, SessionQueueItem, SessionQueueStatus, ) - from invokeai.backend.model_manager.config import AnyModelConfig, SubModelType + from invokeai.backend.model_manager.configs.factory import AnyModelConfig + from invokeai.backend.model_manager.taxonomy import SubModelType class EventServiceBase: @@ -58,15 +62,16 @@ def emit_invocation_started(self, queue_item: "SessionQueueItem", invocation: "B """Emitted when an invocation is started""" self.dispatch(InvocationStartedEvent.build(queue_item, invocation)) - def emit_invocation_denoise_progress( + def emit_invocation_progress( self, queue_item: "SessionQueueItem", invocation: "BaseInvocation", - intermediate_state: PipelineIntermediateState, - progress_image: "ProgressImage", + message: str, + percentage: float | None = None, + image: "ProgressImage | None" = None, ) -> None: - """Emitted at each step during denoising of an invocation.""" - self.dispatch(InvocationDenoiseProgressEvent.build(queue_item, invocation, intermediate_state, progress_image)) + """Emitted at periodically during an invocation""" + self.dispatch(InvocationProgressEvent.build(queue_item, invocation, message, percentage, image)) def emit_invocation_complete( self, queue_item: "SessionQueueItem", invocation: "BaseInvocation", output: "BaseInvocationOutput" @@ -95,14 +100,22 @@ def emit_queue_item_status_changed( """Emitted when a queue item's status changes""" self.dispatch(QueueItemStatusChangedEvent.build(queue_item, batch_status, queue_status)) - def emit_batch_enqueued(self, enqueue_result: "EnqueueBatchResult") -> None: + def emit_batch_enqueued(self, enqueue_result: "EnqueueBatchResult", user_id: str = "system") -> None: """Emitted when a batch is enqueued""" - self.dispatch(BatchEnqueuedEvent.build(enqueue_result)) + self.dispatch(BatchEnqueuedEvent.build(enqueue_result, user_id)) + + def emit_queue_items_retried(self, retry_result: "RetryItemsResult") -> None: + """Emitted when a list of queue items are retried""" + self.dispatch(QueueItemsRetriedEvent.build(retry_result)) def emit_queue_cleared(self, queue_id: str) -> None: """Emitted when a queue is cleared""" self.dispatch(QueueClearedEvent.build(queue_id)) + def emit_recall_parameters_updated(self, queue_id: str, user_id: str, parameters: dict) -> None: + """Emitted when recall parameters are updated""" + self.dispatch(RecallParametersUpdatedEvent.build(queue_id, user_id, parameters)) + # endregion # region Download @@ -123,6 +136,10 @@ def emit_download_cancelled(self, job: "DownloadJob") -> None: """Emitted when a download is cancelled""" self.dispatch(DownloadCancelledEvent.build(job)) + def emit_download_paused(self, job: "DownloadJob") -> None: + """Emitted when a download is paused""" + self.dispatch(DownloadPausedEvent.build(job)) + def emit_download_error(self, job: "DownloadJob") -> None: """Emitted when a download encounters an error""" self.dispatch(DownloadErrorEvent.build(job)) @@ -177,23 +194,42 @@ def emit_model_install_error(self, job: "ModelInstallJob") -> None: # region Bulk image download def emit_bulk_download_started( - self, bulk_download_id: str, bulk_download_item_id: str, bulk_download_item_name: str + self, + bulk_download_id: str, + bulk_download_item_id: str, + bulk_download_item_name: str, + user_id: str = "system", ) -> None: """Emitted when a bulk image download is started""" - self.dispatch(BulkDownloadStartedEvent.build(bulk_download_id, bulk_download_item_id, bulk_download_item_name)) + self.dispatch( + BulkDownloadStartedEvent.build(bulk_download_id, bulk_download_item_id, bulk_download_item_name, user_id) + ) def emit_bulk_download_complete( - self, bulk_download_id: str, bulk_download_item_id: str, bulk_download_item_name: str + self, + bulk_download_id: str, + bulk_download_item_id: str, + bulk_download_item_name: str, + user_id: str = "system", ) -> None: """Emitted when a bulk image download is complete""" - self.dispatch(BulkDownloadCompleteEvent.build(bulk_download_id, bulk_download_item_id, bulk_download_item_name)) + self.dispatch( + BulkDownloadCompleteEvent.build(bulk_download_id, bulk_download_item_id, bulk_download_item_name, user_id) + ) def emit_bulk_download_error( - self, bulk_download_id: str, bulk_download_item_id: str, bulk_download_item_name: str, error: str + self, + bulk_download_id: str, + bulk_download_item_id: str, + bulk_download_item_name: str, + error: str, + user_id: str = "system", ) -> None: """Emitted when a bulk image download has an error""" self.dispatch( - BulkDownloadErrorEvent.build(bulk_download_id, bulk_download_item_id, bulk_download_item_name, error) + BulkDownloadErrorEvent.build( + bulk_download_id, bulk_download_item_id, bulk_download_item_name, error, user_id + ) ) # endregion diff --git a/invokeai/app/services/events/events_common.py b/invokeai/app/services/events/events_common.py index c6a867fb081..c30fa31b75c 100644 --- a/invokeai/app/services/events/events_common.py +++ b/invokeai/app/services/events/events_common.py @@ -1,26 +1,27 @@ -from math import floor from typing import TYPE_CHECKING, Any, ClassVar, Coroutine, Generic, Optional, Protocol, TypeAlias, TypeVar from fastapi_events.handlers.local import local_handler from fastapi_events.registry.payload_schema import registry as payload_schema from pydantic import BaseModel, ConfigDict, Field +from invokeai.app.services.model_install.model_install_common import ModelInstallJob, ModelSource from invokeai.app.services.session_processor.session_processor_common import ProgressImage from invokeai.app.services.session_queue.session_queue_common import ( QUEUE_ITEM_STATUS, BatchStatus, EnqueueBatchResult, + RetryItemsResult, SessionQueueItem, SessionQueueStatus, ) from invokeai.app.services.shared.graph import AnyInvocation, AnyInvocationOutput from invokeai.app.util.misc import get_timestamp -from invokeai.backend.model_manager.config import AnyModelConfig, SubModelType -from invokeai.backend.stable_diffusion.diffusers_pipeline import PipelineIntermediateState +from invokeai.backend.model_manager.configs.factory import AnyModelConfig +from invokeai.backend.model_manager.taxonomy import SubModelType if TYPE_CHECKING: from invokeai.app.services.download.download_base import DownloadJob - from invokeai.app.services.model_install.model_install_common import ModelInstallJob + from invokeai.app.services.model_install.model_install_common import ModelInstallJob, ModelSource class EventBase(BaseModel): @@ -88,6 +89,9 @@ class QueueItemEventBase(QueueEventBase): item_id: int = Field(description="The ID of the queue item") batch_id: str = Field(description="The ID of the queue batch") + origin: str | None = Field(default=None, description="The origin of the queue item") + destination: str | None = Field(default=None, description="The destination of the queue item") + user_id: str = Field(default="system", description="The ID of the user who created the queue item") class InvocationEventBase(QueueItemEventBase): @@ -95,8 +99,6 @@ class InvocationEventBase(QueueItemEventBase): session_id: str = Field(description="The ID of the session (aka graph execution state)") queue_id: str = Field(description="The ID of the queue") - item_id: int = Field(description="The ID of the queue item") - batch_id: str = Field(description="The ID of the queue batch") session_id: str = Field(description="The ID of the session (aka graph execution state)") invocation: AnyInvocation = Field(description="The ID of the invocation") invocation_source_id: str = Field(description="The ID of the prepared invocation's source node") @@ -114,6 +116,9 @@ def build(cls, queue_item: SessionQueueItem, invocation: AnyInvocation) -> "Invo queue_id=queue_item.queue_id, item_id=queue_item.item_id, batch_id=queue_item.batch_id, + origin=queue_item.origin, + destination=queue_item.destination, + user_id=queue_item.user_id, session_id=queue_item.session_id, invocation=invocation, invocation_source_id=queue_item.session.prepared_source_mapping[invocation.id], @@ -121,52 +126,55 @@ def build(cls, queue_item: SessionQueueItem, invocation: AnyInvocation) -> "Invo @payload_schema.register -class InvocationDenoiseProgressEvent(InvocationEventBase): - """Event model for invocation_denoise_progress""" +class InvocationProgressEvent(InvocationEventBase): + """Event model for invocation_progress""" - __event_name__ = "invocation_denoise_progress" + __event_name__ = "invocation_progress" - progress_image: ProgressImage = Field(description="The progress image sent at each step during processing") - step: int = Field(description="The current step of the invocation") - total_steps: int = Field(description="The total number of steps in the invocation") - order: int = Field(description="The order of the invocation in the session") - percentage: float = Field(description="The percentage of completion of the invocation") + message: str = Field(description="A message to display") + percentage: float | None = Field( + default=None, ge=0, le=1, description="The percentage of the progress (omit to indicate indeterminate progress)" + ) + image: ProgressImage | None = Field( + default=None, description="An image representing the current state of the progress" + ) + device: str | None = Field( + default=None, + description="The device processing this session, e.g. 'cuda:1' (set only when running on a CUDA GPU)", + ) @classmethod def build( cls, queue_item: SessionQueueItem, invocation: AnyInvocation, - intermediate_state: PipelineIntermediateState, - progress_image: ProgressImage, - ) -> "InvocationDenoiseProgressEvent": - step = intermediate_state.step - total_steps = intermediate_state.total_steps - order = intermediate_state.order + message: str, + percentage: float | None = None, + image: ProgressImage | None = None, + ) -> "InvocationProgressEvent": + # This is emitted from the session-processor worker thread, which pins its CUDA device via + # TorchDevice.set_session_device(). Resolve that here so the UI can label progress by GPU. + from invokeai.backend.util.devices import TorchDevice + + session_device = TorchDevice.get_session_device() + device = str(session_device) if session_device is not None and session_device.type == "cuda" else None + return cls( queue_id=queue_item.queue_id, item_id=queue_item.item_id, batch_id=queue_item.batch_id, + origin=queue_item.origin, + destination=queue_item.destination, + user_id=queue_item.user_id, session_id=queue_item.session_id, invocation=invocation, invocation_source_id=queue_item.session.prepared_source_mapping[invocation.id], - progress_image=progress_image, - step=step, - total_steps=total_steps, - order=order, - percentage=cls.calc_percentage(step, total_steps, order), + percentage=percentage, + image=image, + message=message, + device=device, ) - @staticmethod - def calc_percentage(step: int, total_steps: int, scheduler_order: float) -> float: - """Calculate the percentage of completion of denoising.""" - if total_steps == 0: - return 0.0 - if scheduler_order == 2: - return floor((step + 1 + 1) / 2) / floor((total_steps + 1) / 2) - # order == 1 - return (step + 1 + 1) / (total_steps + 1) - @payload_schema.register class InvocationCompleteEvent(InvocationEventBase): @@ -184,6 +192,9 @@ def build( queue_id=queue_item.queue_id, item_id=queue_item.item_id, batch_id=queue_item.batch_id, + origin=queue_item.origin, + destination=queue_item.destination, + user_id=queue_item.user_id, session_id=queue_item.session_id, invocation=invocation, invocation_source_id=queue_item.session.prepared_source_mapping[invocation.id], @@ -200,8 +211,6 @@ class InvocationErrorEvent(InvocationEventBase): error_type: str = Field(description="The error type") error_message: str = Field(description="The error message") error_traceback: str = Field(description="The error traceback") - user_id: Optional[str] = Field(default=None, description="The ID of the user who created the invocation") - project_id: Optional[str] = Field(default=None, description="The ID of the user who created the invocation") @classmethod def build( @@ -216,14 +225,15 @@ def build( queue_id=queue_item.queue_id, item_id=queue_item.item_id, batch_id=queue_item.batch_id, + origin=queue_item.origin, + destination=queue_item.destination, + user_id=queue_item.user_id, session_id=queue_item.session_id, invocation=invocation, invocation_source_id=queue_item.session.prepared_source_mapping[invocation.id], error_type=error_type, error_message=error_message, error_traceback=error_traceback, - user_id=getattr(queue_item, "user_id", None), - project_id=getattr(queue_item, "project_id", None), ) @@ -234,11 +244,15 @@ class QueueItemStatusChangedEvent(QueueItemEventBase): __event_name__ = "queue_item_status_changed" status: QUEUE_ITEM_STATUS = Field(description="The new status of the queue item") + status_sequence: int | None = Field( + default=None, + description="A monotonically increasing version for this queue item's visible status lifecycle", + ) error_type: Optional[str] = Field(default=None, description="The error type, if any") error_message: Optional[str] = Field(default=None, description="The error message, if any") error_traceback: Optional[str] = Field(default=None, description="The error traceback, if any") - created_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was created") - updated_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was last updated") + created_at: str = Field(description="The timestamp when the queue item was created") + updated_at: str = Field(description="The timestamp when the queue item was last updated") started_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was started") completed_at: Optional[str] = Field(default=None, description="The timestamp when the queue item was completed") batch_status: BatchStatus = Field(description="The status of the batch") @@ -253,13 +267,17 @@ def build( queue_id=queue_item.queue_id, item_id=queue_item.item_id, batch_id=queue_item.batch_id, + origin=queue_item.origin, + destination=queue_item.destination, + user_id=queue_item.user_id, session_id=queue_item.session_id, status=queue_item.status, + status_sequence=queue_item.status_sequence, error_type=queue_item.error_type, error_message=queue_item.error_message, error_traceback=queue_item.error_traceback, - created_at=str(queue_item.created_at) if queue_item.created_at else None, - updated_at=str(queue_item.updated_at) if queue_item.updated_at else None, + created_at=str(queue_item.created_at), + updated_at=str(queue_item.updated_at), started_at=str(queue_item.started_at) if queue_item.started_at else None, completed_at=str(queue_item.completed_at) if queue_item.completed_at else None, batch_status=batch_status, @@ -279,15 +297,35 @@ class BatchEnqueuedEvent(QueueEventBase): description="The number of invocations initially requested to be enqueued (may be less than enqueued if queue was full)" ) priority: int = Field(description="The priority of the batch") + origin: str | None = Field(default=None, description="The origin of the batch") + user_id: str = Field(default="system", description="The ID of the user who enqueued the batch") @classmethod - def build(cls, enqueue_result: EnqueueBatchResult) -> "BatchEnqueuedEvent": + def build(cls, enqueue_result: EnqueueBatchResult, user_id: str = "system") -> "BatchEnqueuedEvent": return cls( queue_id=enqueue_result.queue_id, batch_id=enqueue_result.batch.batch_id, + origin=enqueue_result.batch.origin, enqueued=enqueue_result.enqueued, requested=enqueue_result.requested, priority=enqueue_result.priority, + user_id=user_id, + ) + + +@payload_schema.register +class QueueItemsRetriedEvent(QueueEventBase): + """Event model for queue_items_retried""" + + __event_name__ = "queue_items_retried" + + retried_item_ids: list[int] = Field(description="The IDs of the queue items that were retried") + + @classmethod + def build(cls, retry_result: RetryItemsResult) -> "QueueItemsRetriedEvent": + return cls( + queue_id=retry_result.queue_id, + retried_item_ids=retry_result.retried_item_ids, ) @@ -369,6 +407,17 @@ def build(cls, job: "DownloadJob") -> "DownloadCancelledEvent": return cls(source=str(job.source)) +@payload_schema.register +class DownloadPausedEvent(DownloadEventBase): + """Event model for download_paused""" + + __event_name__ = "download_paused" + + @classmethod + def build(cls, job: "DownloadJob") -> "DownloadPausedEvent": + return cls(source=str(job.source)) + + @payload_schema.register class DownloadErrorEvent(DownloadEventBase): """Event model for download_error""" @@ -424,7 +473,7 @@ class ModelInstallDownloadStartedEvent(ModelEventBase): __event_name__ = "model_install_download_started" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") local_path: str = Field(description="Where model is downloading to") bytes: int = Field(description="Number of bytes downloaded so far") total_bytes: int = Field(description="Total size of download, including all files") @@ -445,7 +494,7 @@ def build(cls, job: "ModelInstallJob") -> "ModelInstallDownloadStartedEvent": ] return cls( id=job.id, - source=str(job.source), + source=job.source, local_path=job.local_path.as_posix(), parts=parts, bytes=job.bytes, @@ -460,7 +509,7 @@ class ModelInstallDownloadProgressEvent(ModelEventBase): __event_name__ = "model_install_download_progress" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") local_path: str = Field(description="Where model is downloading to") bytes: int = Field(description="Number of bytes downloaded so far") total_bytes: int = Field(description="Total size of download, including all files") @@ -481,7 +530,7 @@ def build(cls, job: "ModelInstallJob") -> "ModelInstallDownloadProgressEvent": ] return cls( id=job.id, - source=str(job.source), + source=job.source, local_path=job.local_path.as_posix(), parts=parts, bytes=job.bytes, @@ -496,11 +545,11 @@ class ModelInstallDownloadsCompleteEvent(ModelEventBase): __event_name__ = "model_install_downloads_complete" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") @classmethod def build(cls, job: "ModelInstallJob") -> "ModelInstallDownloadsCompleteEvent": - return cls(id=job.id, source=str(job.source)) + return cls(id=job.id, source=job.source) @payload_schema.register @@ -510,11 +559,11 @@ class ModelInstallStartedEvent(ModelEventBase): __event_name__ = "model_install_started" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") @classmethod def build(cls, job: "ModelInstallJob") -> "ModelInstallStartedEvent": - return cls(id=job.id, source=str(job.source)) + return cls(id=job.id, source=job.source) @payload_schema.register @@ -524,14 +573,21 @@ class ModelInstallCompleteEvent(ModelEventBase): __event_name__ = "model_install_complete" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") key: str = Field(description="Model config record key") total_bytes: Optional[int] = Field(description="Size of the model (may be None for installation of a local path)") + config: AnyModelConfig = Field(description="The installed model's config") @classmethod def build(cls, job: "ModelInstallJob") -> "ModelInstallCompleteEvent": assert job.config_out is not None - return cls(id=job.id, source=str(job.source), key=(job.config_out.key), total_bytes=job.total_bytes) + return cls( + id=job.id, + source=job.source, + key=(job.config_out.key), + total_bytes=job.total_bytes, + config=job.config_out, + ) @payload_schema.register @@ -541,11 +597,11 @@ class ModelInstallCancelledEvent(ModelEventBase): __event_name__ = "model_install_cancelled" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") @classmethod def build(cls, job: "ModelInstallJob") -> "ModelInstallCancelledEvent": - return cls(id=job.id, source=str(job.source)) + return cls(id=job.id, source=job.source) @payload_schema.register @@ -555,7 +611,7 @@ class ModelInstallErrorEvent(ModelEventBase): __event_name__ = "model_install_error" id: int = Field(description="The ID of the install job") - source: str = Field(description="Source of the model; local path, repo_id or url") + source: ModelSource = Field(description="Source of the model; local path, repo_id or url") error_type: str = Field(description="The name of the exception") error: str = Field(description="A text description of the exception") @@ -563,7 +619,7 @@ class ModelInstallErrorEvent(ModelEventBase): def build(cls, job: "ModelInstallJob") -> "ModelInstallErrorEvent": assert job.error_type is not None assert job.error is not None - return cls(id=job.id, source=str(job.source), error_type=job.error_type, error=job.error) + return cls(id=job.id, source=job.source, error_type=job.error_type, error=job.error) class BulkDownloadEventBase(EventBase): @@ -572,6 +628,7 @@ class BulkDownloadEventBase(EventBase): bulk_download_id: str = Field(description="The ID of the bulk image download") bulk_download_item_id: str = Field(description="The ID of the bulk image download item") bulk_download_item_name: str = Field(description="The name of the bulk image download item") + user_id: str = Field(default="system", description="The ID of the user who initiated the download") @payload_schema.register @@ -582,12 +639,17 @@ class BulkDownloadStartedEvent(BulkDownloadEventBase): @classmethod def build( - cls, bulk_download_id: str, bulk_download_item_id: str, bulk_download_item_name: str + cls, + bulk_download_id: str, + bulk_download_item_id: str, + bulk_download_item_name: str, + user_id: str = "system", ) -> "BulkDownloadStartedEvent": return cls( bulk_download_id=bulk_download_id, bulk_download_item_id=bulk_download_item_id, bulk_download_item_name=bulk_download_item_name, + user_id=user_id, ) @@ -599,12 +661,17 @@ class BulkDownloadCompleteEvent(BulkDownloadEventBase): @classmethod def build( - cls, bulk_download_id: str, bulk_download_item_id: str, bulk_download_item_name: str + cls, + bulk_download_id: str, + bulk_download_item_id: str, + bulk_download_item_name: str, + user_id: str = "system", ) -> "BulkDownloadCompleteEvent": return cls( bulk_download_id=bulk_download_id, bulk_download_item_id=bulk_download_item_id, bulk_download_item_name=bulk_download_item_name, + user_id=user_id, ) @@ -618,11 +685,31 @@ class BulkDownloadErrorEvent(BulkDownloadEventBase): @classmethod def build( - cls, bulk_download_id: str, bulk_download_item_id: str, bulk_download_item_name: str, error: str + cls, + bulk_download_id: str, + bulk_download_item_id: str, + bulk_download_item_name: str, + error: str, + user_id: str = "system", ) -> "BulkDownloadErrorEvent": return cls( bulk_download_id=bulk_download_id, bulk_download_item_id=bulk_download_item_id, bulk_download_item_name=bulk_download_item_name, error=error, + user_id=user_id, ) + + +@payload_schema.register +class RecallParametersUpdatedEvent(QueueEventBase): + """Event model for recall_parameters_updated""" + + __event_name__ = "recall_parameters_updated" + + user_id: str = Field(description="The ID of the user whose recall parameters were updated") + parameters: dict[str, Any] = Field(description="The recall parameters that were updated") + + @classmethod + def build(cls, queue_id: str, user_id: str, parameters: dict[str, Any]) -> "RecallParametersUpdatedEvent": + return cls(queue_id=queue_id, user_id=user_id, parameters=parameters) diff --git a/invokeai/app/services/events/events_fastapievents.py b/invokeai/app/services/events/events_fastapievents.py index 8279d3bb344..90e1402773d 100644 --- a/invokeai/app/services/events/events_fastapievents.py +++ b/invokeai/app/services/events/events_fastapievents.py @@ -1,47 +1,54 @@ -# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654) - import asyncio import threading -from queue import Empty, Queue from fastapi_events.dispatcher import dispatch -from invokeai.app.services.events.events_common import ( - EventBase, -) - -from .events_base import EventServiceBase +from invokeai.app.services.events.events_base import EventServiceBase +from invokeai.app.services.events.events_common import EventBase class FastAPIEventService(EventServiceBase): - def __init__(self, event_handler_id: int) -> None: + def __init__(self, event_handler_id: int, loop: asyncio.AbstractEventLoop) -> None: self.event_handler_id = event_handler_id - self._queue = Queue[EventBase | None]() + self._queue = asyncio.Queue[EventBase | None]() self._stop_event = threading.Event() - asyncio.create_task(self._dispatch_from_queue(stop_event=self._stop_event)) + self._loop = loop + + # We need to store a reference to the task so it doesn't get GC'd + # See: https://docs.python.org/3/library/asyncio-task.html#creating-tasks + self._background_tasks: set[asyncio.Task[None]] = set() + task = self._loop.create_task(self._dispatch_from_queue(stop_event=self._stop_event)) + self._background_tasks.add(task) + task.add_done_callback(self._background_tasks.remove) super().__init__() def stop(self, *args, **kwargs): self._stop_event.set() - self._queue.put(None) + self._loop.call_soon_threadsafe(self._queue.put_nowait, None) def dispatch(self, event: EventBase) -> None: - self._queue.put(event) + if self._loop.is_closed(): + # The event loop was closed during shutdown. Events can no longer be dispatched; + # silently drop this one so the generation thread can wind down cleanly. + return + self._loop.call_soon_threadsafe(self._queue.put_nowait, event) async def _dispatch_from_queue(self, stop_event: threading.Event): """Get events on from the queue and dispatch them, from the correct thread""" while not stop_event.is_set(): try: - event = self._queue.get(block=False) + event = await self._queue.get() if not event: # Probably stopping continue # Leave the payloads as live pydantic models dispatch(event, middleware_id=self.event_handler_id, payload_schema_dump=False) - except Empty: - await asyncio.sleep(0.1) - pass - except asyncio.CancelledError as e: raise e # Raise a proper error + except Exception: + import logging + + logging.getLogger("InvokeAI").error( + f"Error dispatching event {getattr(event, '__event_name__', event)}", exc_info=True + ) diff --git a/invokeai/app/services/external_generation/__init__.py b/invokeai/app/services/external_generation/__init__.py new file mode 100644 index 00000000000..b933811d293 --- /dev/null +++ b/invokeai/app/services/external_generation/__init__.py @@ -0,0 +1,23 @@ +from invokeai.app.services.external_generation.external_generation_base import ( + ExternalGenerationServiceBase, + ExternalProvider, +) +from invokeai.app.services.external_generation.external_generation_common import ( + ExternalGeneratedImage, + ExternalGenerationRequest, + ExternalGenerationResult, + ExternalProviderStatus, + ExternalReferenceImage, +) +from invokeai.app.services.external_generation.external_generation_default import ExternalGenerationService + +__all__ = [ + "ExternalGenerationRequest", + "ExternalGenerationResult", + "ExternalGeneratedImage", + "ExternalGenerationService", + "ExternalGenerationServiceBase", + "ExternalProvider", + "ExternalProviderStatus", + "ExternalReferenceImage", +] diff --git a/invokeai/app/services/external_generation/errors.py b/invokeai/app/services/external_generation/errors.py new file mode 100644 index 00000000000..f61a6a8c730 --- /dev/null +++ b/invokeai/app/services/external_generation/errors.py @@ -0,0 +1,28 @@ +class ExternalGenerationError(Exception): + """Base error for external generation.""" + + +class ExternalProviderNotFoundError(ExternalGenerationError): + """Raised when no provider is registered for a model.""" + + +class ExternalProviderNotConfiguredError(ExternalGenerationError): + """Raised when a provider is missing required credentials.""" + + +class ExternalProviderCapabilityError(ExternalGenerationError): + """Raised when a request is not supported by provider capabilities.""" + + +class ExternalProviderRequestError(ExternalGenerationError): + """Raised when a provider rejects the request or returns an error.""" + + +class ExternalProviderRateLimitError(ExternalProviderRequestError): + """Raised when a provider returns HTTP 429 (rate limit exceeded).""" + + retry_after: float | None + + def __init__(self, message: str, retry_after: float | None = None) -> None: + super().__init__(message) + self.retry_after = retry_after diff --git a/invokeai/app/services/external_generation/external_generation_base.py b/invokeai/app/services/external_generation/external_generation_base.py new file mode 100644 index 00000000000..2145ff5ca42 --- /dev/null +++ b/invokeai/app/services/external_generation/external_generation_base.py @@ -0,0 +1,40 @@ +from __future__ import annotations + +from abc import ABC, abstractmethod +from logging import Logger + +from invokeai.app.services.config import InvokeAIAppConfig +from invokeai.app.services.external_generation.external_generation_common import ( + ExternalGenerationRequest, + ExternalGenerationResult, + ExternalProviderStatus, +) + + +class ExternalProvider(ABC): + provider_id: str + + def __init__(self, app_config: InvokeAIAppConfig, logger: Logger) -> None: + self._app_config = app_config + self._logger = logger + + @abstractmethod + def is_configured(self) -> bool: + raise NotImplementedError + + @abstractmethod + def generate(self, request: ExternalGenerationRequest) -> ExternalGenerationResult: + raise NotImplementedError + + def get_status(self) -> ExternalProviderStatus: + return ExternalProviderStatus(provider_id=self.provider_id, configured=self.is_configured()) + + +class ExternalGenerationServiceBase(ABC): + @abstractmethod + def generate(self, request: ExternalGenerationRequest) -> ExternalGenerationResult: + raise NotImplementedError + + @abstractmethod + def get_provider_statuses(self) -> dict[str, ExternalProviderStatus]: + raise NotImplementedError diff --git a/invokeai/app/services/external_generation/external_generation_common.py b/invokeai/app/services/external_generation/external_generation_common.py new file mode 100644 index 00000000000..f14bff52dd2 --- /dev/null +++ b/invokeai/app/services/external_generation/external_generation_common.py @@ -0,0 +1,52 @@ +from __future__ import annotations + +from dataclasses import dataclass +from typing import Any + +from PIL.Image import Image as PILImageType + +from invokeai.backend.model_manager.configs.external_api import ExternalApiModelConfig, ExternalGenerationMode + + +@dataclass(frozen=True) +class ExternalReferenceImage: + image: PILImageType + + +@dataclass(frozen=True) +class ExternalGenerationRequest: + model: ExternalApiModelConfig + mode: ExternalGenerationMode + prompt: str + seed: int | None + num_images: int + width: int + height: int + image_size: str | None + init_image: PILImageType | None + mask_image: PILImageType | None + reference_images: list[ExternalReferenceImage] + metadata: dict[str, Any] | None + provider_options: dict[str, Any] | None = None + + +@dataclass(frozen=True) +class ExternalGeneratedImage: + image: PILImageType + seed: int | None = None + + +@dataclass(frozen=True) +class ExternalGenerationResult: + images: list[ExternalGeneratedImage] + seed_used: int | None = None + provider_request_id: str | None = None + provider_metadata: dict[str, Any] | None = None + content_filters: dict[str, str] | None = None + + +@dataclass(frozen=True) +class ExternalProviderStatus: + provider_id: str + configured: bool + message: str | None = None diff --git a/invokeai/app/services/external_generation/external_generation_default.py b/invokeai/app/services/external_generation/external_generation_default.py new file mode 100644 index 00000000000..d6a266753b3 --- /dev/null +++ b/invokeai/app/services/external_generation/external_generation_default.py @@ -0,0 +1,369 @@ +from __future__ import annotations + +import dataclasses +import time +from logging import Logger +from typing import TYPE_CHECKING + +from PIL import Image +from PIL.Image import Image as PILImageType + +from invokeai.app.services.external_generation.errors import ( + ExternalProviderCapabilityError, + ExternalProviderNotConfiguredError, + ExternalProviderNotFoundError, + ExternalProviderRateLimitError, +) +from invokeai.app.services.external_generation.external_generation_base import ( + ExternalGenerationServiceBase, + ExternalProvider, +) +from invokeai.app.services.external_generation.external_generation_common import ( + ExternalGeneratedImage, + ExternalGenerationRequest, + ExternalGenerationResult, + ExternalProviderStatus, +) +from invokeai.backend.model_manager.configs.external_api import ExternalApiModelConfig, ExternalImageSize +from invokeai.backend.model_manager.starter_models import STARTER_MODELS + +if TYPE_CHECKING: + from invokeai.app.services.model_records import ModelRecordServiceBase + + +class ExternalGenerationService(ExternalGenerationServiceBase): + def __init__( + self, + providers: dict[str, ExternalProvider], + logger: Logger, + record_store: ModelRecordServiceBase | None = None, + ) -> None: + self._providers = providers + self._logger = logger + self._record_store = record_store + + def generate(self, request: ExternalGenerationRequest) -> ExternalGenerationResult: + provider = self._providers.get(request.model.provider_id) + if provider is None: + raise ExternalProviderNotFoundError(f"No external provider registered for '{request.model.provider_id}'") + + if not provider.is_configured(): + raise ExternalProviderNotConfiguredError(f"Provider '{request.model.provider_id}' is missing credentials") + + request = self._refresh_model_capabilities(request) + resize_to_original_inpaint_size = _get_resize_target_for_inpaint(request) + request = self._bucket_request(request) + request = self._drop_unsupported_capabilities(request) + + self._validate_request(request) + result = self._generate_with_retry(provider, request) + + if resize_to_original_inpaint_size is None: + return result + + width, height = resize_to_original_inpaint_size + return _resize_result_images(result, width, height) + + _MAX_RETRIES = 3 + _DEFAULT_RETRY_DELAY = 10.0 + _MAX_RETRY_DELAY = 60.0 + + def _generate_with_retry( + self, provider: ExternalProvider, request: ExternalGenerationRequest + ) -> ExternalGenerationResult: + for attempt in range(self._MAX_RETRIES): + try: + return provider.generate(request) + except ExternalProviderRateLimitError as exc: + if attempt == self._MAX_RETRIES - 1: + raise + delay = min(exc.retry_after or self._DEFAULT_RETRY_DELAY, self._MAX_RETRY_DELAY) + self._logger.warning( + "Rate limited by %s (attempt %d/%d), retrying in %.0fs", + request.model.provider_id, + attempt + 1, + self._MAX_RETRIES, + delay, + ) + time.sleep(delay) + raise ExternalProviderRateLimitError("Rate limit exceeded after all retries") + + def get_provider_statuses(self) -> dict[str, ExternalProviderStatus]: + return {provider_id: provider.get_status() for provider_id, provider in self._providers.items()} + + def _validate_request(self, request: ExternalGenerationRequest) -> None: + capabilities = request.model.capabilities + + self._logger.debug( + "Validating external request provider=%s model=%s mode=%s supported=%s", + request.model.provider_id, + request.model.provider_model_id, + request.mode, + capabilities.modes, + ) + + if request.mode not in capabilities.modes: + raise ExternalProviderCapabilityError(f"Mode '{request.mode}' is not supported by {request.model.name}") + + if request.reference_images and not capabilities.supports_reference_images: + raise ExternalProviderCapabilityError(f"Reference images are not supported by {request.model.name}") + + if capabilities.max_reference_images is not None: + if len(request.reference_images) > capabilities.max_reference_images: + raise ExternalProviderCapabilityError( + f"{request.model.name} supports at most {capabilities.max_reference_images} reference images" + ) + + if capabilities.max_images_per_request is not None and request.num_images > capabilities.max_images_per_request: + raise ExternalProviderCapabilityError( + f"{request.model.name} supports at most {capabilities.max_images_per_request} images per request" + ) + + if capabilities.max_image_size is not None: + if request.width > capabilities.max_image_size.width or request.height > capabilities.max_image_size.height: + raise ExternalProviderCapabilityError( + f"{request.model.name} supports a maximum size of {capabilities.max_image_size.width}x{capabilities.max_image_size.height}" + ) + + if capabilities.allowed_aspect_ratios: + aspect_ratio = _format_aspect_ratio(request.width, request.height) + if aspect_ratio not in capabilities.allowed_aspect_ratios: + size_ratio = None + if capabilities.aspect_ratio_sizes: + size_ratio = _ratio_for_size(request.width, request.height, capabilities.aspect_ratio_sizes) + if size_ratio is None or size_ratio not in capabilities.allowed_aspect_ratios: + ratio_label = size_ratio or aspect_ratio + raise ExternalProviderCapabilityError( + f"{request.model.name} does not support aspect ratio {ratio_label}" + ) + + required_modes = capabilities.input_image_required_for or ["img2img", "inpaint"] + if request.mode in required_modes and request.init_image is None: + raise ExternalProviderCapabilityError( + f"Mode '{request.mode}' requires an init image for {request.model.name}" + ) + + if request.mode == "inpaint" and request.mask_image is None: + raise ExternalProviderCapabilityError( + f"Mode '{request.mode}' requires a mask image for {request.model.name}" + ) + + def _drop_unsupported_capabilities(self, request: ExternalGenerationRequest) -> ExternalGenerationRequest: + """Silently drop request fields the selected model does not support so workflow-editor runs don't fail + when users wire them in regardless.""" + capabilities = request.model.capabilities + updates: dict[str, object] = {} + + if request.seed is not None and not capabilities.supports_seed: + self._logger.debug( + "Dropping seed for %s: model does not support seed control", + request.model.name, + ) + updates["seed"] = None + + if updates: + return dataclasses.replace(request, **updates) + return request + + def _refresh_model_capabilities(self, request: ExternalGenerationRequest) -> ExternalGenerationRequest: + if self._record_store is None: + return request + + try: + record = self._record_store.get_model(request.model.key) + except Exception: + record = None + + if not isinstance(record, ExternalApiModelConfig): + return request + + if record.key != request.model.key: + return request + + if record.provider_id != request.model.provider_id: + return request + + if record.provider_model_id != request.model.provider_model_id: + return request + + record = _apply_starter_overrides(record) + + if record == request.model: + return request + + return ExternalGenerationRequest( + model=record, + mode=request.mode, + prompt=request.prompt, + seed=request.seed, + num_images=request.num_images, + width=request.width, + height=request.height, + image_size=request.image_size, + init_image=request.init_image, + mask_image=request.mask_image, + reference_images=request.reference_images, + metadata=request.metadata, + provider_options=request.provider_options, + ) + + def _bucket_request(self, request: ExternalGenerationRequest) -> ExternalGenerationRequest: + capabilities = request.model.capabilities + if not capabilities.allowed_aspect_ratios: + return request + + aspect_ratio = _format_aspect_ratio(request.width, request.height) + size = None + if capabilities.aspect_ratio_sizes: + size = capabilities.aspect_ratio_sizes.get(aspect_ratio) + + if size is not None: + if request.width == size.width and request.height == size.height: + return request + return self._bucket_to_size(request, size.width, size.height, aspect_ratio) + + if aspect_ratio in capabilities.allowed_aspect_ratios: + return request + + if not capabilities.aspect_ratio_sizes: + return request + + closest = _select_closest_ratio( + request.width, + request.height, + capabilities.allowed_aspect_ratios, + ) + if closest is None: + return request + + size = capabilities.aspect_ratio_sizes.get(closest) + if size is None: + return request + + return self._bucket_to_size(request, size.width, size.height, closest) + + def _bucket_to_size( + self, + request: ExternalGenerationRequest, + width: int, + height: int, + ratio: str, + ) -> ExternalGenerationRequest: + self._logger.info( + "Bucketing external request provider=%s model=%s %sx%s -> %sx%s (ratio %s)", + request.model.provider_id, + request.model.provider_model_id, + request.width, + request.height, + width, + height, + ratio, + ) + + return ExternalGenerationRequest( + model=request.model, + mode=request.mode, + prompt=request.prompt, + seed=request.seed, + num_images=request.num_images, + width=width, + height=height, + image_size=request.image_size, + init_image=_resize_image(request.init_image, width, height, "RGB"), + mask_image=_resize_image(request.mask_image, width, height, "L"), + reference_images=request.reference_images, + metadata=request.metadata, + provider_options=request.provider_options, + ) + + +def _format_aspect_ratio(width: int, height: int) -> str: + divisor = _gcd(width, height) + return f"{width // divisor}:{height // divisor}" + + +def _select_closest_ratio(width: int, height: int, ratios: list[str]) -> str | None: + ratio = width / height + parsed: list[tuple[str, float]] = [] + for value in ratios: + parsed_ratio = _parse_ratio(value) + if parsed_ratio is not None: + parsed.append((value, parsed_ratio)) + if not parsed: + return None + return min(parsed, key=lambda item: abs(item[1] - ratio))[0] + + +def _ratio_for_size(width: int, height: int, sizes: dict[str, ExternalImageSize]) -> str | None: + for ratio, size in sizes.items(): + if size.width == width and size.height == height: + return ratio + return None + + +def _parse_ratio(value: str) -> float | None: + if ":" not in value: + return None + left, right = value.split(":", 1) + try: + numerator = float(left) + denominator = float(right) + except ValueError: + return None + if denominator == 0: + return None + return numerator / denominator + + +def _gcd(a: int, b: int) -> int: + while b: + a, b = b, a % b + return a + + +def _resize_image(image: PILImageType | None, width: int, height: int, mode: str) -> PILImageType | None: + if image is None: + return None + if image.width == width and image.height == height: + return image + return image.convert(mode).resize((width, height), Image.Resampling.LANCZOS) + + +def _get_resize_target_for_inpaint(request: ExternalGenerationRequest) -> tuple[int, int] | None: + if request.mode != "inpaint" or request.init_image is None: + return None + return request.init_image.width, request.init_image.height + + +def _resize_result_images(result: ExternalGenerationResult, width: int, height: int) -> ExternalGenerationResult: + resized_images = [ + ExternalGeneratedImage( + image=generated.image + if generated.image.width == width and generated.image.height == height + else generated.image.resize((width, height), Image.Resampling.LANCZOS), + seed=generated.seed, + ) + for generated in result.images + ] + return ExternalGenerationResult( + images=resized_images, + seed_used=result.seed_used, + provider_request_id=result.provider_request_id, + provider_metadata=result.provider_metadata, + content_filters=result.content_filters, + ) + + +def _apply_starter_overrides(model: ExternalApiModelConfig) -> ExternalApiModelConfig: + source = model.source or f"external://{model.provider_id}/{model.provider_model_id}" + starter_match = next((starter for starter in STARTER_MODELS if starter.source == source), None) + if starter_match is None: + return model + updates: dict[str, object] = {} + if starter_match.capabilities is not None: + updates["capabilities"] = starter_match.capabilities + if starter_match.default_settings is not None: + updates["default_settings"] = starter_match.default_settings + if not updates: + return model + return model.model_copy(update=updates) diff --git a/invokeai/app/services/external_generation/image_utils.py b/invokeai/app/services/external_generation/image_utils.py new file mode 100644 index 00000000000..a23c1f11d66 --- /dev/null +++ b/invokeai/app/services/external_generation/image_utils.py @@ -0,0 +1,19 @@ +from __future__ import annotations + +import base64 +import io + +from PIL import Image +from PIL.Image import Image as PILImageType + + +def encode_image_base64(image: PILImageType, format: str = "PNG") -> str: + buffer = io.BytesIO() + image.save(buffer, format=format) + return base64.b64encode(buffer.getvalue()).decode("ascii") + + +def decode_image_base64(encoded: str) -> PILImageType: + data = base64.b64decode(encoded) + image = Image.open(io.BytesIO(data)) + return image.convert("RGB") diff --git a/invokeai/app/services/external_generation/providers/__init__.py b/invokeai/app/services/external_generation/providers/__init__.py new file mode 100644 index 00000000000..9926302addf --- /dev/null +++ b/invokeai/app/services/external_generation/providers/__init__.py @@ -0,0 +1,6 @@ +from invokeai.app.services.external_generation.providers.alibabacloud import AlibabaCloudProvider +from invokeai.app.services.external_generation.providers.gemini import GeminiProvider +from invokeai.app.services.external_generation.providers.openai import OpenAIProvider +from invokeai.app.services.external_generation.providers.seedream import SeedreamProvider + +__all__ = ["AlibabaCloudProvider", "GeminiProvider", "OpenAIProvider", "SeedreamProvider"] diff --git a/invokeai/app/services/external_generation/providers/alibabacloud.py b/invokeai/app/services/external_generation/providers/alibabacloud.py new file mode 100644 index 00000000000..6a1d01baefa --- /dev/null +++ b/invokeai/app/services/external_generation/providers/alibabacloud.py @@ -0,0 +1,410 @@ +from __future__ import annotations + +import io +import time + +import requests +from PIL import Image +from PIL.Image import Image as PILImageType + +from invokeai.app.services.external_generation.errors import ExternalProviderRequestError +from invokeai.app.services.external_generation.external_generation_base import ExternalProvider +from invokeai.app.services.external_generation.external_generation_common import ( + ExternalGeneratedImage, + ExternalGenerationRequest, + ExternalGenerationResult, +) +from invokeai.app.services.external_generation.image_utils import decode_image_base64, encode_image_base64 + +# Models that support the synchronous multimodal-generation endpoint with messages format +_SYNC_MODELS = { + "qwen-image-2.0-pro", + "qwen-image-2.0", + "qwen-image-max", + "wan2.6-t2i", + "qwen-image-edit-max", +} + +# Models that use the async image-generation endpoint with flat prompt format. +# Currently no shipped starter model uses this path, but it is retained because +# users may install custom external models via `external://alibabacloud/