역전파 그래프를 통해 역전파를 두 번 실행하는 것은 가끔씩 유용한 경우가 있습니다. 예를 들어 고차 미분을 계산할 때입니다. 그러나 이중 역전파를 지원하려면 autograd의 이해와 주의가 필요합니다. 단일 역전파를 지원한다고 반드시 이중 역전파를 지원하는 것은 아닙니다. 이 튜토리얼에서는 어떻게 사용자 정의 함수로 이중 역전파를 지원하는지 알려주고 주의해야 할 점들을 안내합니다.
이중 역전파를 사용하는 사용자 정의 autograd 함수를 사용할 때, 함수 내에서 어떻게 동작하는지 언제 계산 결과가 기록되고 언제 기록되지 않는지 이해하는 것이 중요합니다. 특히 전체 과정에서 save_for_backward 가 어떻게 동작하는지 아는 것이 가장 중요합니다.
사용자 정의 함수는 암묵적으로 grad 모드에 두 가지 방식으로 영향을 줍니다:
- 순전파를 진행하는 동안 autograd는 순전파 함수안에서 동작하는 어떤 연산도 그래프에 기록하지 않습니다. 순전파가 끝나고 사용자 정의 함수의 역전파는 순전파의 결과의 grad_fn 이 됩니다.
- 역전파가 진행되는 동안 create_graph가 지정되어 있다면 autograd는 역전파의 연산을 그래프에 기록합니다.
다음으로, save_for_backward 가 위의 내용과 어떻게 상호작용하는지 이해하기 위해서, 몇 가지 예시를 살펴보겠습니다:
간단한 제곱 함수를 생각해 보겠습니다. 이 함수는 역전파를 위해서 입력 텐서를 저장합니다. 역전파 과정을 autograd가 기록할 수 있다면 이중 역전파는 자동으로 동작합니다. 따라서 역전파를 위해 입력을 저장할 때는 일반적으로 걱정할 필요가 없습니다. 입력이 grad를 요구하는 텐서부터 계산된 함수라면 grad_fn을 가지고 있고 이를 통해서 변화도가 올바르게 전파되기 때문입니다.
import torch
class Square(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
# Because we are saving one of the inputs use `save_for_backward`
# Save non-tensors and non-inputs/non-outputs directly on ctx
ctx.save_for_backward(x)
return x**2
@staticmethod
def backward(ctx, grad_out):
# A function support double backward automatically if autograd
# is able to record the computations performed in backward
x, = ctx.saved_tensors
return grad_out * 2 * x
# Use double precision because finite differencing method magnifies errors
x = torch.rand(3, 3, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(Square.apply, x)
# Use gradcheck to verify second-order derivatives
torch.autograd.gradgradcheck(Square.apply, x)torchviz로 그래프를 시각화해서 작동원리를 확인할 수 있습니다.
import torchviz
x = torch.tensor(1., requires_grad=True).clone()
out = Square.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), {"grad_x": grad_x, "x": x, "out": out})x에 대한 변화도가 그 자체로 x의 함수라는 것을 확인할 수 있습니다(dout/dx = 2x). 이 함수에 대한 그래프도 제대로 생성되었습니다.
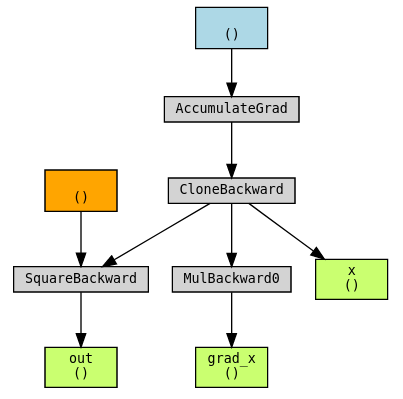
이전 예제를 조금 변형하면 입력대신 출력을 저장할수 있습니다. 출력도 grad_fn을 가지고있기에 방식을 비슷합니다.
class Exp(torch.autograd.Function):
# Simple case where everything goes well
@staticmethod
def forward(ctx, x):
# This time we save the output
result = torch.exp(x)
# Note that we should use `save_for_backward` here when
# the tensor saved is an ouptut (or an input).
ctx.save_for_backward(result)
return result
@staticmethod
def backward(ctx, grad_out):
result, = ctx.saved_tensors
return result * grad_out
x = torch.tensor(1., requires_grad=True, dtype=torch.double).clone()
# Validate our gradients using gradcheck
torch.autograd.gradcheck(Exp.apply, x)
torch.autograd.gradgradcheck(Exp.apply, x)torchviz로 그래프 시각화하기:
out = Exp.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), {"grad_x": grad_x, "x": x, "out": out})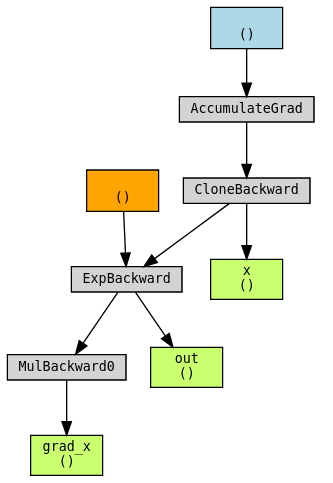
중간 결과를 저장하는것은 좀 더 어렵습니다. 다음을 구현하여 보여드리겠습니다:
sinh(x) := \frac{e^x - e^{-x}}{2}
sinh의 도함수는 cosh이므로, 순전파의 중간결과인 exp(x) 와 exp(-x) 를 역전파 계산에 재사용하면 효율적입니다.
중간 결과를 직접 저장하여 역전파에 사용하면 안 됩니다. 순전파가 no-grad 모드에서 실행되기 때문에, 만약 순전파의 중간 결과가 역전파에서 변화도를 계산하는 데 사용되면 변화도의 역전파 그래프에 중간 결과를 계산한 연산들이 포함되지 않습니다. 결과적으로 변화도가 부정확해집니다.
class Sinh(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
expx = torch.exp(x)
expnegx = torch.exp(-x)
ctx.save_for_backward(expx, expnegx)
# In order to be able to save the intermediate results, a trick is to
# include them as our outputs, so that the backward graph is constructed
return (expx - expnegx) / 2, expx, expnegx
@staticmethod
def backward(ctx, grad_out, _grad_out_exp, _grad_out_negexp):
expx, expnegx = ctx.saved_tensors
grad_input = grad_out * (expx + expnegx) / 2
# We cannot skip accumulating these even though we won't use the outputs
# directly. They will be used later in the second backward.
grad_input += _grad_out_exp * expx
grad_input -= _grad_out_negexp * expnegx
return grad_input
def sinh(x):
# Create a wrapper that only returns the first output
return Sinh.apply(x)[0]
x = torch.rand(3, 3, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(sinh, x)
torch.autograd.gradgradcheck(sinh, x)torchviz로 그래프 시각화하기:
out = sinh(x)
grad_x, = torch.autograd.grad(out.sum(), x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})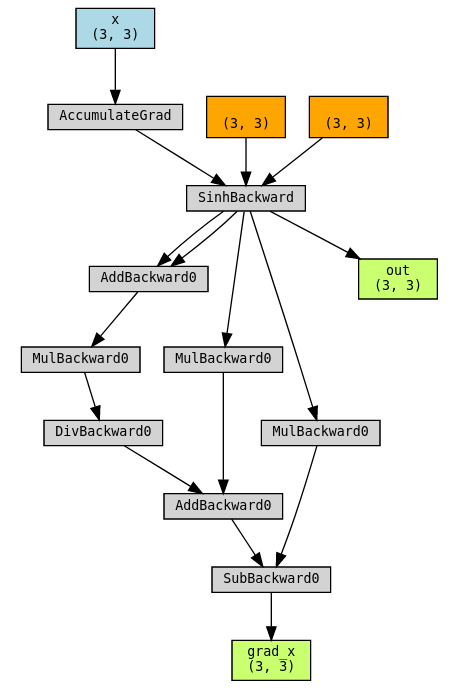
중간 결과를 출력으로 반환하지 않으면 어떤 일이 발생하는지 살펴보겠습니다. grad_x 는 역전파 그래프를 아예 갖지 못합니다. 이것은 grad_x 가 오직 grad를 필요로 하지 않는 exp 와 expnegx 의 함수이기 때문입니다.
class SinhBad(torch.autograd.Function):
# This is an example of what NOT to do!
@staticmethod
def forward(ctx, x):
expx = torch.exp(x)
expnegx = torch.exp(-x)
ctx.expx = expx
ctx.expnegx = expnegx
return (expx - expnegx) / 2
@staticmethod
def backward(ctx, grad_out):
expx = ctx.expx
expnegx = ctx.expnegx
grad_input = grad_out * (expx + expnegx) / 2
return grad_inputtorchviz로 그래프 시각화하기. grad_x 가 그래프에 포함되지 않는것을 확인하세요!
out = SinhBad.apply(x)
grad_x, = torch.autograd.grad(out.sum(), x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})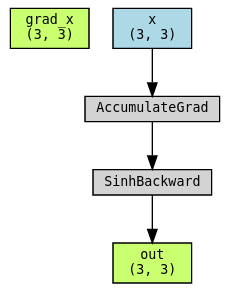
마지막으로 autograd가 함수의 역전파에 대한 변화도를 추적할 수 없는 상황을 살펴보겠습니다. cube_backward가 SciPy나 NumPy 같은 외부 라이브러리를 사용하거나 C++로 구현되었다고 가정해 보겠습니다. 이런 경우는 CubeBackward라는 또 다른 사용자 정의 함수를 생성하여 cube_backward의 역전파도 수동으로 지정하는 것입니다!
def cube_forward(x):
return x**3
def cube_backward(grad_out, x):
return grad_out * 3 * x**2
def cube_backward_backward(grad_out, sav_grad_out, x):
return grad_out * sav_grad_out * 6 * x
def cube_backward_backward_grad_out(grad_out, x):
return grad_out * 3 * x**2
class Cube(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return cube_forward(x)
@staticmethod
def backward(ctx, grad_out):
x, = ctx.saved_tensors
return CubeBackward.apply(grad_out, x)
class CubeBackward(torch.autograd.Function):
@staticmethod
def forward(ctx, grad_out, x):
ctx.save_for_backward(x, grad_out)
return cube_backward(grad_out, x)
@staticmethod
def backward(ctx, grad_out):
x, sav_grad_out = ctx.saved_tensors
dx = cube_backward_backward(grad_out, sav_grad_out, x)
dgrad_out = cube_backward_backward_grad_out(grad_out, x)
return dgrad_out, dx
x = torch.tensor(2., requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(Cube.apply, x)
torch.autograd.gradgradcheck(Cube.apply, x)torchviz로 그래프 시각화하기:
out = Cube.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})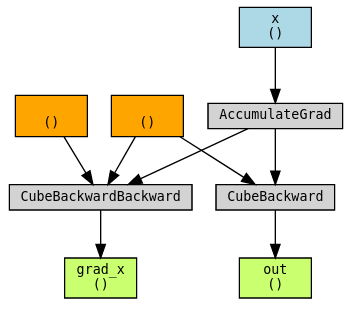
결론적으로 사용자 정의 함수의 이중 역전파 작동여부는 autograd가 역전파 과정을 추적할 수 있느냐에 달려 있습니다. 처음 두 예제에서는 이중 역전파가 자동으로 동작하는 경우를 보여주었고, 세 번째와 네 번째 예제는 추적되지 않는 역전파 함수를 추적 가능하게 만드는 방법을 설명했습니다.